

在画heatmap的时候,往往由于某种数据分析需要,需要获得聚类后的heatmap的col和row的顺序。这里展示如何从pheatmap的聚类结果中提取我们需要的信息。
这里通过产生随机数据来演示。
data <- replicate(20, rnorm(50))
rownames(data) <- paste("Gene", c(1:nrow(data)))
colnames(data) <- paste("Sample", c(1:ncol(data)))
out <- pheatmap(data,
show_rownames=T, cluster_cols=T, cluster_rows=T, scale="row",
cex=1, clustering_distance_rows="euclidean", cex=1,
clustering_distance_cols="euclidean", clustering_method="complete", border_color=FALSE)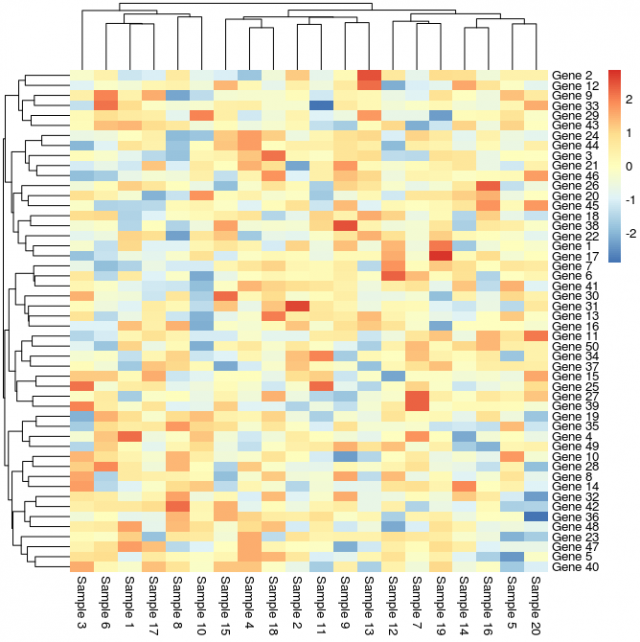
#Re-order original data (genes) to match ordering in heatmap (top-to-bottom) rownames(data[out$tree_row[["order"]],]) [1] "Gene 2" "Gene 12" "Gene 9" "Gene 33" "Gene 29" "Gene 43" "Gene 24" [8] "Gene 44" "Gene 3" "Gene 21" "Gene 46" "Gene 26" "Gene 20" "Gene 45" [15] "Gene 18" "Gene 38" "Gene 22" "Gene 1" "Gene 17" "Gene 7" "Gene 6" [22] "Gene 41" "Gene 30" "Gene 31" "Gene 13" "Gene 16" "Gene 11" "Gene 50" [29] "Gene 34" "Gene 37" "Gene 15" "Gene 25" "Gene 27" "Gene 39" "Gene 19" [36] "Gene 35" "Gene 4" "Gene 49" "Gene 10" "Gene 28" "Gene 8" "Gene 14" [43] "Gene 32" "Gene 42" "Gene 36" "Gene 48" "Gene 23" "Gene 47" "Gene 5" [50] "Gene 40"
#Re-order original data (samples) to match ordering in heatmap (left-to-right) colnames(data[,out$tree_col[["order"]]]) [1] "Sample 3" "Sample 6" "Sample 1" "Sample 17" "Sample 8" "Sample 10" [7] "Sample 15" "Sample 4" "Sample 18" "Sample 2" "Sample 11" "Sample 9" [13] "Sample 13" "Sample 12" "Sample 7" "Sample 19" "Sample 14" "Sample 16" [19] "Sample 5" "Sample 20"
将排序后,行的名称存入文件
rowdata = rownames(data[out$tree_row[["order"]],]) write.table(rowdata,file='rowdata.txt', row.names=F, col.names = F, quote=F)
同理,将排序的列的名称存入文件
coldata = rownames(data[out$tree_col[["order"]],]) write.table(coldata,file='coldata', row.names=F, col.names = F, quote=F)
关于write.table的使用说明:
Write.table()函数的用法read.table()非常相似,只不过它把数据框写入文件而不是从文件中读取。参数和选项:
write.table(x, file = "", append = FALSE, quote = TRUE, sep = " ",eol = "\n", na = "NA", dec = ".", row.names = TRUE,col.names = TRUE, qmethod = c("escape", "double"))函数Write.table()的选项值及说明
| 选项值 | 说明 |
| x | 要写入的对象名 |
| file | 文件名(缺省时对象直接被“写”在屏幕上) |
| append | 如果为TRUE则在写入数据时不删除目标文件中可能已存在的数据,采取往后添加的方式 |
| quote | 一个逻辑型或者数值型向量:如果为TRUE,则字符型变量和因子写在双引号("")中,若quote是数值型向量则代表将欲写在("")中的那些列的列标 |
| sep | 文件中的字段分隔符 |
| eol | 使用在每行最后的字符("\n"表示回车) |
| na | 表示确实数据的字符 |
| dec | 用来表示小数点的字符 |
| row.names | 一个逻辑值,决定行名是否写入文件,或指定要作为行名写入文件的字符型向量 |
| col.names | 一个逻辑值(决定列名是否写入文件);或指定一个要作为列名写入文件中的字符向量 |
| qmethod | 若quote=TRUE,则此参数用来指定字符型变量中的双引号("")如何处理;若参数值为"escape"(或者"e",缺省)每个"都用\"替换,若值为"d",则每个"都用""替换 |