

碱基平衡性
碱基复杂度与碱基多样性是一个意思;复杂度高,碱基即平衡。低多样性(low diversity)即碱基不平衡,指碱基的组成太单纯了,种类少。碱基复杂度本来无关紧要,从前除了设计PCR的时候考虑高GC(GC-rich)以外,基本没人思考这个问题,没人觉得这是一个问题。随着Illumina的二代测序技术风靡全球,独占鳌头,这个不起眼的概念意外地变得重要起来。
一、概念
对于一个基因来说,它所包含的碱基种类越多,则碱基复杂度越高;如果各种碱基的百分含量越接近一致,则碱基组成越平衡。
假设一个DNA片段,它的全部碱基都是A,AAAAAAAAAAAAAAAAAAAAAAAA,显然其碱基组成是极度不平衡的。
DNA碱基有4种:AGCT。所以碱基最平衡的情况就是:%A=%G=%C=%T=25%,比如这样的DNA片段:AGCTAGCTAGCTAGCTAGCTAGCTAGCTAGCT。
以上是从纵的方面讲的。对于二代测序,更重要的是横的方面。假设12个基因整整齐齐站成一排,第一个位置的12个碱基如果都是A,复杂度太低,严重不平衡;如果A和G各有6个,虽然平衡了,但是复杂度还是不够;如果AGCT各有3个,最复杂,也最平衡;如果A3个G4个C4个,T1个,虽然复杂,但是严重不平衡。
二、影响
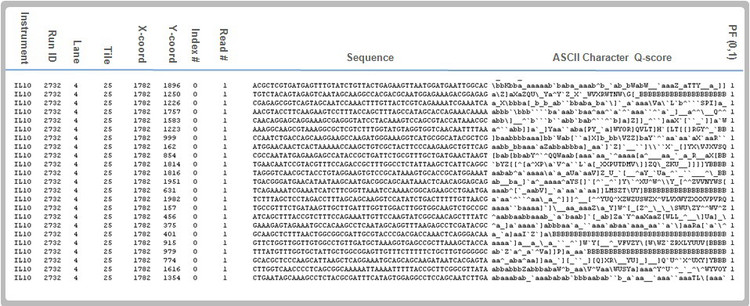
4张滤色片,在4个波长处收集信号,然后合成,进行cluster定位及其他运算。如果缺少一种碱基,该波长的照片就是全黑的,没有信号,无法完成图片合并以及cluster定位,导致数据浪费。
需要特别注意碱基复杂度的二代测序应用:PCR产物测序,特别是用于鉴定细菌、真菌以及其他物种的16S rRNAPCR产物测序;小RNA测序;甲基化测序。
三、增加碱基复杂度的方法
文库:
- 把不同的文库混合在一起。
- 如果没有其他文库,那么掺入人基因组DNA文库、人外显子组文库或者PhiX标准品。这些都是已知碱基平衡的。
引物:
- 对于PCR产物来说,只要引物长度不同,就能自然错开,增加碱基复杂度。
- 采用多对序列不同的引物来完成扩增,然后将产物混合在一起。
Barcodes:
- 仔细挑选barcode组合,确保每个位置都有3-4种碱基且碱基分布均匀。
##barcode 选择
很多情况下,我们需要把多个样本混合在一起,在同一个通道(lane)里完成测序。像转录组测序、miRNA测序、lncRNA测序、ChIP测序等等,通常每个样本所需要的数据量都比较少,远少于HiSeq一个通道的产出能力,混合样本是非常常见。以转录组测序为例,一个样本测序60 M reads (8G PF data) ,就能够满足绝大部分研究所需。而HiSeq2500-PE125的一条通道,使用V4试剂,数据产出>480 M reads。为了充分利用测序仪产能,节约成本,需要把7~8个RNA样本混合起来。
为了能够把测序数据按样本分离(de-multiplexing),在构建文库(library)的时候,需要用不同的标签序列(index, 也叫barcode)对文库进行标记。只有文库作了记号,数据才能区分。
Barcode的选择是一门技术活。如果barcode组合不佳,标签序列测序质量下降,部分或者全部标签碱基识别不正确,将导致部分数据无法归属到任何一个样本,成为undetermined数据,造成浪费。
一、如何判断barcode组合好坏
- 碱基平衡。好的barcode组合必须是“4种碱基达到平衡”的,或者说碱基复杂度高。具体就是:
a. 在一组barcode的每一个位置,同时存在A、G、C、T四种碱基,不缺少任何一种碱基;
b. 这4种碱基的比例接近,最好各1/4,分别为25%左右,没有任何一种碱基特别多或者特别少。 - 激光平衡。 受客观条件限制
a.试剂盒提供的barcode种类有限
b.有些barcode已经被其他样本占用,导致可选的余地受限制,这就导致barcode组合经常无法达到理想的碱基平衡要求。退而求其次,要力保“红绿激光达到平衡”。
在所有型号的Illumina测序仪中,A和C两种碱基共用一种激光,由波长660 nm的红激光激发;G和T共用一种激光,由波长532 nm的绿激光激发。对于一组barcode的每一个位置,如果A+C的总数与G+T的总数相接近,可以在一定程度上弥补碱基不平衡的负面作用。
3、激光平衡是次优选择,不得已而为之。它虽然可以在一定程度上提高barcode测序质量,减少de-multiplexing出问题的可能性,但是并不是说,只要激光平衡了,测序数据的分离就一定不受影响。
4、如果barcode组合碱基也不平衡,激光也不平衡,则de-multiplexing风险非常高。
二、Barcode组合举例
- 好的组合。
Illumina推荐的12个样本barcode组合如下。
| 编号 | 序列 |
|---|---|
| 01 | ATC ACG |
| 02 | CGA TGT |
| 03 | TTA GGC |
| 04 | TGA CCA |
| 05 | ACA GTG |
| 06 | GCC AAT |
| 07 | CAG ATC |
| 08 | ACT TGA |
| 09 | GAT CAG |
| 10 | TAG CTT |
| 11 | GGC TAC |
| 12 | CTT GTA |
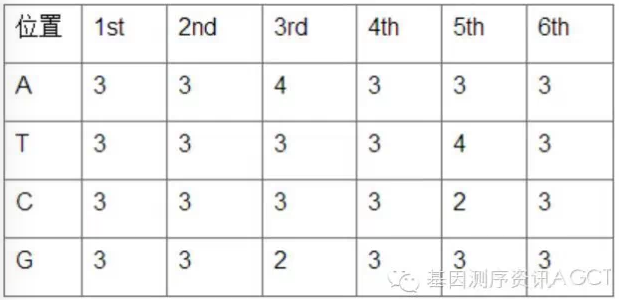
以第一个位置(纵列)为例,A:G:C:T=3:3:3:3=1:1:1:1。实际上,该barcode组合每个位置的碱基比例都接近1:1,碱基平衡度近乎完美。
- 不好的组合
下面的组合有缺陷。比如说,第1个位置只有A和C两种碱基,A、C都属于红激光,导致绿激光没有信号,碱基和激光都不平衡。
AGT TCC ACT GAT ACG AGC ACT CCT CAA AAG CAA CCA CAC CAG
三、Barcode碱基不平衡的后果
- 如果barcode组合的碱基组成不平衡,会导致测序进行到这些碱基时,软件对测序信号的处理出现障碍,不能准确地识别这些碱基(base-calling),表现为QV值降低,%Q30曲线波动。
- 在这种情况下,运用生物信息软件对测序数据进行数据分离(de-multiplexing)出现困难,部分数据不能准确分离,成为undetermined 数据的一部分,造成undetermined数据增多,可分离的数据减少。
- 如果测序数据的总量很多,远大于全部样本数据量期望值的总和,则问题有可能不那么严重,全部或者大部分样本仍然可能分离到足够的数据量。
- 万一样本性质特殊,反应效率低;或者混合样本之间竞争和抑制严重,导致测序数据总量在期望值附近,余量很少;或者其中个别样本数据量特别少,这时如果undetermined数据比例过高,就会导致部分或者全部样本的数据量不够用。
- 混合样本补数据是一个非常麻烦的问题,成本极高。如果一组样本中只有个别样本需要补数据,由于文库是混合在一起的,其他样本也不得不跟着重测一次。这是困难之一。困难之二,如果数据缺口比较小,本来可以与其他样本混合,搭个便车,可是,进行第二次混合的时候,经常会遇到barcode冲突或者碱基不平衡,拼lane非常困难,往往要等很长时间,才有合适的机会。
四、实验证明de-multiplexing成功,该barcode组合今后是否一定好用
- 如果barcode组合碱基平衡,则无论样本怎么变,该组合一定好用。
- 如果barcode组合的碱基组成不理想,即使以前的实验证明好用,不等于今后一定好用。下一次测序效果可能好,也可能不好。
- 这是由于不同的项目样本不同,有可能导致两种后果:
a.数据总量在期望值附近,余地不够多,de-multiplexing后部分样本数据量不够;
b.如果新的样本本身也碱基不平衡,read 1测序质量很差,会影响到barcode和read2的测序质量。当然,情况b责任不在barcode,即使barcode很好,数据还是不够。
五、补救措施
如果满足以下两个条件:
a. 混合样本的数据总量足够,只是由于barcode质量不好,导致de-multiplexing后部分或全部样本数据量不够;
b. 排除QV值低的barcode碱基后,其余质量好的barcode碱基仍然足够用来区分全部样本;
那么,可以通过改变de-multiplexing算法来为每个样本获得尽量多的数据。比如去掉信号识别模糊的碱基,或者增加mismatch碱基的数目,重新运行de-multiplexing程序。
六、样本少于4种,不可能碱基平衡,怎么办
如果样本数少于4种,每一个位置的碱基最多只有3种,不可能碱基平衡,怎么办呢?这时一定要保证激光平衡。Illumina推荐了3种low-level pooling的barcode组合:
2个样本: :—:|:—-: #6|GCC AAT #12|CTT GTA 3个样本: :—-:|:—-: #4|TGACCA #6|GCCAAT #12|CTTGTA 6个样本: :—:|:—: #2|CGATGT #4|TGACCA #5|ACAGTG #6|GCCAAT #7|CAGATC #12|CTTGTA
这3种组合包含一个共同内核:6号和12号。6号和12号组合是百分百激光平衡的,每一个位置的碱基(纵列,即GC、CT、CT、AG、AT和TA)都分别属于不同的激光。只要barcode组合中包含6号和12号,就能满足最基本的要求,不至于颗粒无收。6号和12号是barcode组合的核心,不可或缺。