

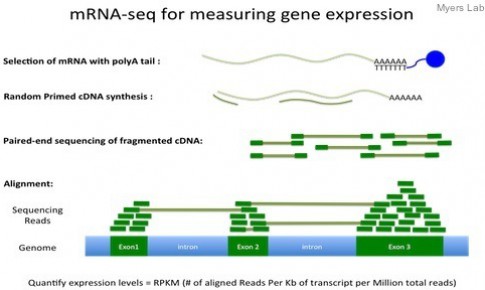
小编注:近年来RNA-Seq被广泛应用,衡量基因表达水平的方法也开始多样化,例如RPK, RPKM, FPKM, TPM等。那他们之间有什么样的区别、以及怎样换算呢。最近看到一篇不错的博客,这里与大家分享。
What the FPKM? A review of RNA-Seq expression units
This post covers the units used in RNA-Seq that are, unfortunately, often misused and misunderstood. I' ll try to clear up a bit of the confusion here.
The first thing one should remember is that without between sample normalization (a topic for a later post), NONE of these units are comparable across experiments. This is a result of RNA-Seq being a relative measurement, not an absolute one.
Preliminaries
Throughout this post “read” refers to both single-end or paired-end reads. The concept of counting is the same with either type of read, as each read represents a fragment that was sequenced.
When saying “feature”, I’m referring to an expression feature, by which I mean a genomic region containing a sequence that can normally appear in an RNA-Seq experiment (e.g. gene, isoform, exon).
Finally, I use the random variable 


Counts
“Counts” usually refers to the number of reads that align to a particular feature. I’ll refer to counts by the random variable

where 
Since counts are NOT scaled by the length of the feature, all units in this category are not comparable within a sample without adjusting for the feature length. This means you can’t sum the counts over a set of features to get the expression of that set (e.g. you can’t sum isoform counts to get gene counts).
Counts are often used by differential expression methods since they are naturally represented by a counting model, such as a negative binomial (NB2).
Effective counts
When eXpress came out, they began reporting “effective counts.” This is basically the same thing as standard counts, with the difference being that they are adjusted for the amount of bias in the experiment. To compute effective counts:
![]() .
.
The intuition here is that if the effective length is much shorter than the actual length, then in an experiment with no bias you would expect to see more counts. Thus, the effective counts are scaling the observed counts up.
Counts per million
Counts per million (CPM) mapped reads are counts scaled by the number of fragments you sequenced (

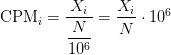
I’m not sure where this unit first appeared, but I’ve seen it used with edgeR and talked about briefly in the limma voom paper.
Within sample normalization
As noted in the counts section, the number of fragments you see from a feature depends on its length. Therefore, in order to compare features of different length you should normalize counts by the length of the feature. Doing so allows the summation of expression across features to get the expression of a group of features (think a set of transcripts which make up a gene).
Again, the methods in this section allow for comparison of features with different length WITHIN a sample but not BETWEEN samples.
TPM
Transcripts per million (TPM) is a measurement of the proportion of transcripts in your pool of RNA.
Since we are interested in taking the length into consideration, a natural measurement is the rate, counts per base (
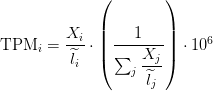
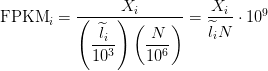{kind=link}
TPM has a very nice interpretation when you’re looking at transcript abundances. As the name suggests, the interpretation is that if you were to sequence one million full length transcripts, TPM is the number of transcripts you would have seen of type
I’m fairly certain TPM is attributed to Bo Li et. al. in the original RSEM paper.
RPKM/FPKM
Reads per kilobase of exon per million reads mapped (RPKM), or the more generic FPKM (substitute reads with fragments) are essentially the same thing. Contrary to some misconceptions, FPKM is not 2 * RPKM if you have paired-end reads. FPKM == RPKM if you have single-end reads, and saying RPKM when you have paired-end reads is just weird, so don’t do it :).
A few years ago when the Mortazavi et. al. paper came out and introduced RPKM, I remember many people referring to the method which they used to compute expression (termed the “rescue method”) as RPKM. This also happened with the Cufflinks method. People would say things like, “We used the RPKM method to compute expression” when they meant to say they used the rescue method or Cufflinks method. I’m happy to report that I haven’t heard this as much recently, but I still hear it every now and then. Therefore, let’s clear one thing up: FPKM is NOT a method, it is simply a unit of expression.
FPKM takes the same rate we discussed in the TPM section and instead of dividing it by the sum of rates, divides it by the total number of reads sequenced (
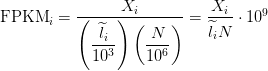 The interpretation of FPKM is as follows: if you were to sequence this pool of RNA again, you expect to see
The interpretation of FPKM is as follows: if you were to sequence this pool of RNA again, you expect to see 

Relationship between TPM and FPKM
The relationship between TPM and FPKM is derived by Lior Pachter in a review of transcript quantification methods (
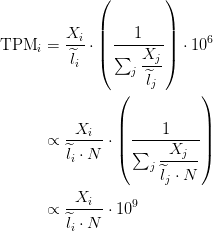
If you have FPKM, you can easily compute TPM:
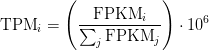
Wagner et. al. discuss some of the benefits of TPM over FPKM here and advocate the use of TPM.
I hope this clears up some confusion or helps you see the relationship between these units. In the near future I plan to write about how to use sequencing depth normalization with these different units so you can compare several samples to each other.
R code
I’ve included some R code below for computing effective counts, TPM, and FPKM. I’m sure a few of those logs aren’t necessary, but I don’t think they’ll hurt.
countToTpm
原文来自:https://haroldpimentel.wordpress.com/2014/05/08/what-the-fpkm-a-review-rna-seq-expression-units/
来自外部的引用