

在样本量的估算过程中我们经常会使用到Ⅰ类和Ⅱ类错误,Ⅰ类错误的取值往往是0.05,Ⅱ类错误的取值往往是0.1或者0.2。那么Ⅰ类和Ⅱ类错误分别代表什么意思呢?又是如果出现在了样本量的计算公式中的呢?本文就此问题作一讨论。
首先介绍Ⅰ类和Ⅱ类错误的概念。我们知道统计推断是用样本量去推论总体,那么在这个推论的过程中我们无外乎离不开两种结局,1是对了,2是错了。错了就是犯错误,错又有两种错法,1种是总体是相同的,你说不同;还有1种是总体是不同的,你说相同。这就分别是Ⅰ类和Ⅱ类错误的概念。如下图:
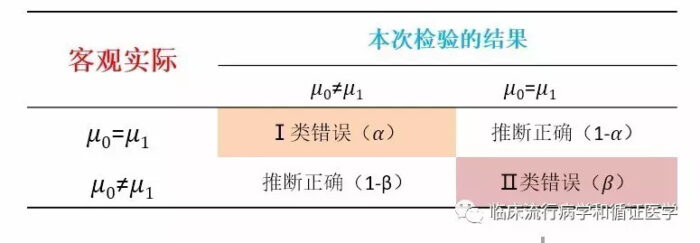
举个例子说明,如果某个药物事实上是无效的,而我们的研究却说它的有效的,这就是Ⅰ类错误。而Ⅱ类错误是某个药物事实上是有效的,而我们却说其是无效的。在临床研究中,没有人想去犯错误。所以我们计算样本量的目的,就是在不犯Ⅰ类错误的前提下,尽可能地少犯Ⅱ类错误。在此条件下,我们就会有更大的机会去发现真正有疗效的药物的疗效。
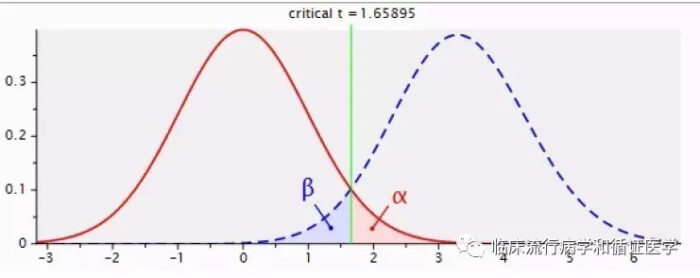
在样本量固定的时候,若Ⅰ类错误下降Ⅱ类错误就会上升,若Ⅰ类错误上升Ⅱ类错误就会下降,如果我们想同时减少Ⅰ类和Ⅱ类错误,就只能增加样本量。如下图,随着绿色垂线的移动,两者此消彼长:
对于使用样本量计算这一过程来说,了解了上面的内容,其实就已足够。但是一定还有人想知道样本量计算的公式是怎么推导的。下面以均数检验为例进行简单的说明。样本量的估算包括参数估计和假设检验,参数估计对应着精度分析,假设检验对应着把握度分析。首先来说精度分析,精度分析就是考虑一个统计量的可信区间有多大,它也是参数估计的样本量推导过程。
假设yi符合一个正态的独立同分布,那么推导过程如下:

再说把握度的分析,它对应着假设检验的样本量估算过程。同样以最简单的两独立样本均数比较为例推导。由于在微信内公式编辑非常困难,以下内容以图片展示。



是不是有点儿蒙?这个推导的确不好理解。但是还是最简单的推断过程,除此之外还有率的推导,还有多组的推导和多因素的推导……,呃,想想就头大啊。