

这次笔记的内容是多元线性回归的SPSS操作及解读。
在线性回归中,残差是一个非常重要的概念,它是估计值与观测值之差,表示因变量中除了分析的自变量外其他所有未进入模型的因素引起的变异,即不能由分析自变量估计的部分,在图形上表示观测值到拟合线的距离(注意不是垂直于拟合线的距离)。
适用条件
(1)线性趋势。因变量与自变量存在线性关系,一般通过散点图(简单线性相关)或散点图矩阵(多重线性回归)来做出简单的判断。此外,残差分析也可以考察线性趋势,偏残差图是更为专业的判断方法。如明显不成线性关系,应进行变量变换修正或改用其他分析。
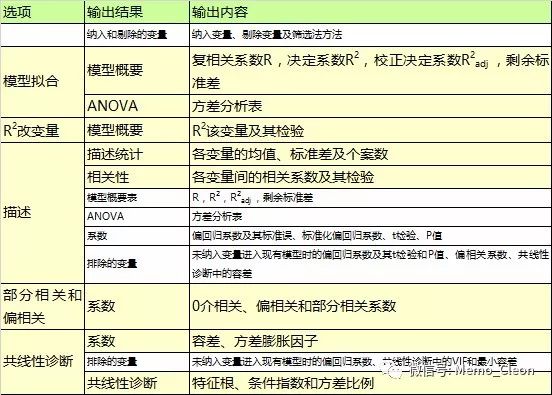
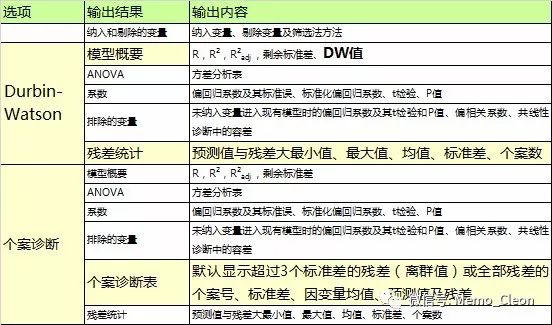
(2)独立性。因变量各观测间相互独立,即任意两个观测的残差的协方差为0。可用Durbin-Watson检验是否存在自相关。
(3)正态性。对自变量的任一个线性组合,因变量均服从正态分布。此处正态分布意为对某个自变量取多个相同的值,对应的多个因变量观测值呈正态分布。但在实际获得的样本中,某一个自变量的固定的取值往往只有有限几个甚至只有1个,其对应的因变量随机观测值也只有几个甚至1个,是没有办法直接进行考察的。在模型中转换为考察残差是否符合正态分布。
(4)方差齐性。同正态分布类似,模型需要利用残差图考察残差是否满足方差齐性。方差不齐可进行加权的最小二乘法。
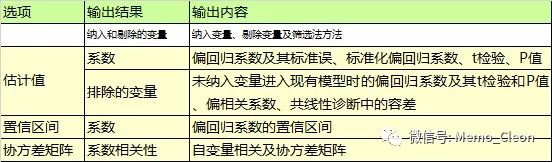
(5)各自变量间不存在多重共线。存在多重共线可导致结果与客观事实不符、估计方程不稳定等诸多问题。逐步回归可以限制有较强关系的自变量进入方程,如存在多重共线,可以剔除某个造成共线性的自变量,或合并自变量,也可改用领回归、主成分回归、偏最小二乘法回归等。多重共线可以利用容差、方差膨胀因子、特征根、条件指数、方差比例、相关系数以及残差图等多种方法考察。
(6)因变量为连续变量,自变量不限。在实际操作中,遇到自变量为分类变量的时候,可用最优尺度回归(分类回归)。
多元线性回归建立模型并不难,但需要认证考察多元线性分析的条件,以及建立的模型是否能够最优的拟合数据。分析步骤:
(1)适用条件考察及处理:线性趋势、独立、正态、方差齐、不存在多重共线等,同时要注意强影响点。
(2)建立回归模型,并进行模型和偏回归系数的假设检验。
(3)模型拟合优劣考察:复相关系数R,决定系数R2,校正决定系数R2adj,残差均方或剩余标准差、赤池信息准则AIC、Cp。
特别说明:纳入那些变量进行分析是由研究者根据专业和经验结合统计结果决定,而不是单单根据统计结果来决定。当自变量较多需要进行筛选自变量时,不同的筛选方法、不同的纳入剔除标准,也会得到完全不同的结果,入选的不一定是最好的,没有纳入的也未必没有统计学意义,回归是为了控制混杂因素分析影响因素,还是为了估计与预测,不同的回归模型可能对某种用途是好的,对另外一种可能就不是最好的。本示例仅为演示SPSS操作。示例数据来自孙振球主编的《医学统计学》第三版。收集了27名糖尿病人的血清总胆固醇(TC)、甘油三脂(TG)、空腹胰岛素(RI)、糖化血红蛋白(HbAc1。本文图片中由于个人在软件录入时书写错误写成了HbAa1c)、空腹血糖(Glu)的测量值,试建立血糖与其他几项指标关系的多重线性回归方程。
SPSS操作步骤
(1)数据录入
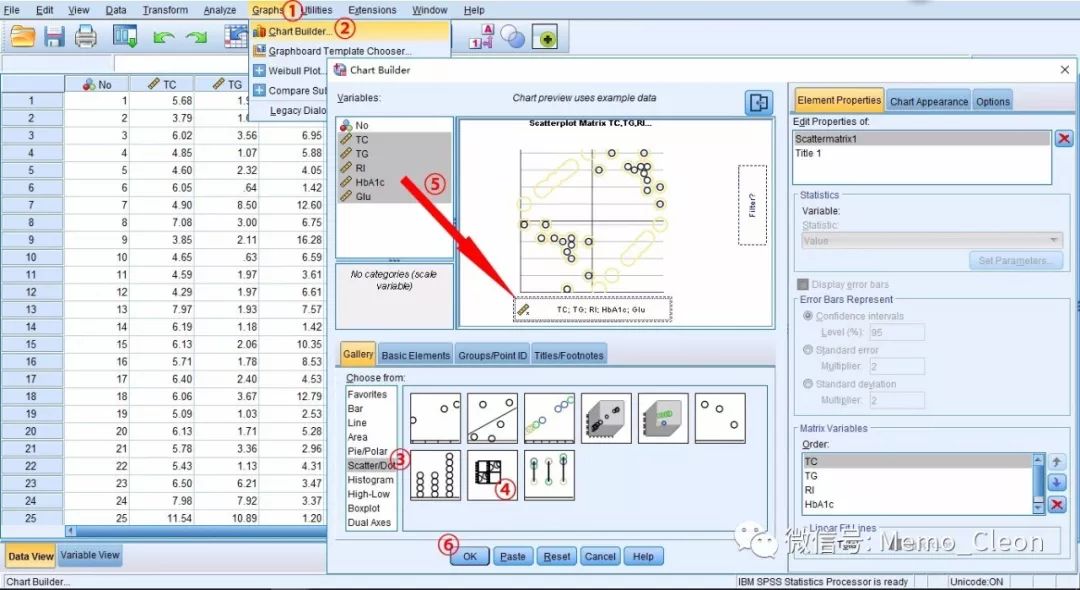
(2)线性趋势考察:Graphs>>Chart Bulider
选择散点图/点图(Scatter/Dot),双击散点图矩阵(Scatterplot Matrix),将要分析的所有变量拖入横坐标的Scatter Matrix框,OK
(3)线性回归:Analyze>>Regression>>Linear……
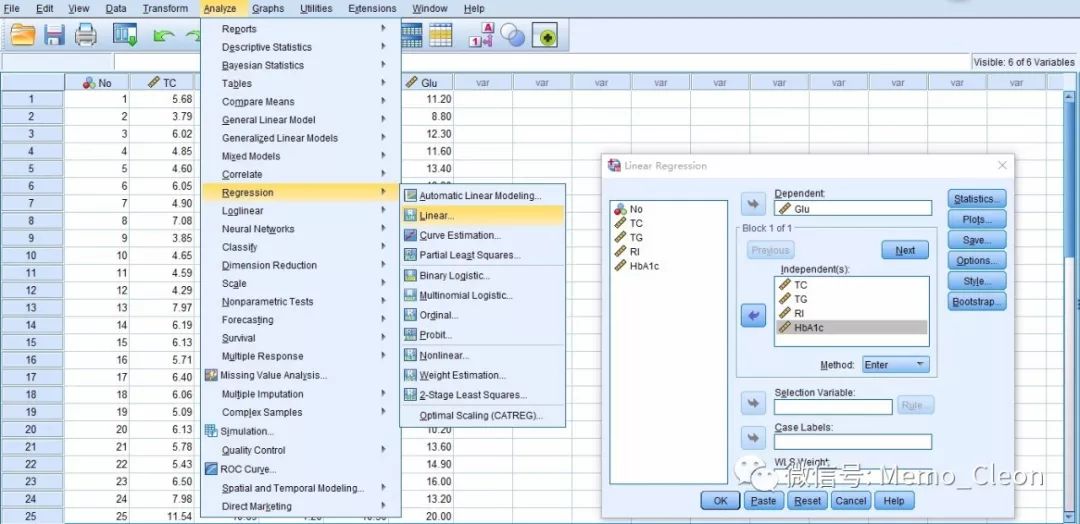
- Dependent(因变量):选入Glu;
- Independent(自变量):选入TC、TG、RI和HbAc1;
变量筛选方法(Method):Stepwise
变量筛选方法SPSS提供了强行进入法(Enter)、逐步回归法(Stepwise)、剔除法(Remove)、向后移除法(Backward)以及向前选择法(Forward)。利用区块(Block)可以实现对不同的变量采用不同的筛选办法,将采用同一筛选方法的变量放在一个区块内即可。
Enter:不涉及变量筛选,所选自变量全部纳入模型。
Forward:所有自变量与因变量分别进行简单的线性回归拟合,选出最重要的候选变量(有统计学意义且P值最小的自变量)引入模型,然后在已引入一个自变量的模型中,将剩余的自变量分别引入,找到有统计学意义且P值最小的组合,然后进行下一步的自变量引入,直至剩余的所有自变量均无统计学意义。
Backward:与Fordward相反,该法首先拟合包含所有自变量的模型,然后依次剔除不重要的变量(P值最大且无统计学意义)
Stepwise:结合了Forward和Backward法。在逐步引入自变量的同时,考察已引入模型的自变量是否还有统计学意义,如果没有则进行剔除。
Remove:规定为Remove的自变量从模型中强行剔除,一般与Block连用。
除了上述方法,还有一种理论上的最佳方法:最优子集法(Best Subset),该法是将所有自变量的可能组合都拟合一遍,然后选出最佳的模型。SPSS中在自动建模(Automatic Linear modeling)中实现。
Selection Variables(筛选变量):可通过Rule建立筛选条件,满足条件的记录进行回归分析。这跟Date>>Select Cases的功能类似。
Case Labels:可选中某一变量作为每条记录的标签。
WLS Weight:选入权重变量,实现加权最小二乘法的回归分析。
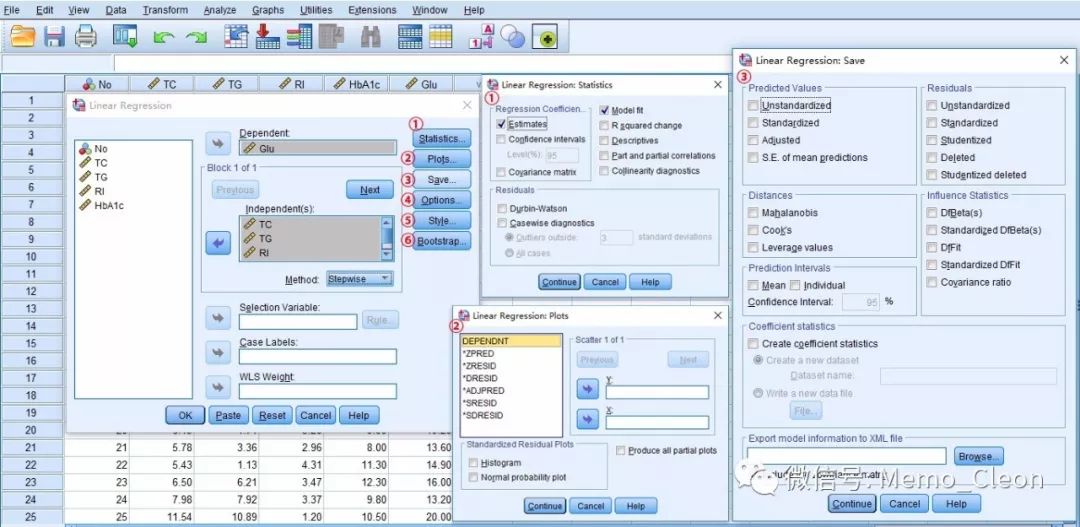
Statistics…对话框:为更好的演示,本例选中所有复选框。
回归系数(Regression Coefficient):估计值、置信区间、协方差矩阵。
模型拟合检验(Model fit)、R2改变量、描述(Descriptives)、部分相关和偏相关(Part and Partial correlations)、共线性诊断(Collinearity diagnositics)。
残差部分:提供Durbin-Watson检验和个案诊断。Durbin-Watson统计量用于检验残差是否存在自相关(独立),个案诊断可用来寻找l离群点。
Plots…对话框:提供作图选项。绘图可以辅助确认正态性、线性、方差齐性假设,在探测离群值、非观测值及强影响点时也非常有用。除了可以直接利用该对话框进行作图,也可以先生成新的变量,然后利用图形构建器来作图。本例将ZRESID 选入Y,ZPRED选入X,构建散点图进行方差齐性的检验;同时选中Histogram和Normal probability plot进行正态性检验;选中Produce all partial plots进行线性趋势检验。
- 可供选择的变量有DEPENDNT(因变量)、ZPRED(标准化预测值)、ZRESID(标准化残差)、DRESID(删除残差)、ADJPRED(校正的预测值)、SRESID(学生化残差)、SDRESID(学生化删除残差)。利用标准化预测值对标准化残差做散点图可以检查线性和方差齐性,利用学生化残差可以探测离群值。
标准化残差图(Standardized Residual Plots): Histogram(标准化残差的直方图)、Normal probability plot(标准化残差的正态概率图)。输出含有正态分布曲线的标准化残差的直方图、P-P图,可以查看是否满足正态分布。
生成所有自变量的偏残差图(Produce all partial plots)*l:偏残差图是每一个自变量与其他自变量回归残差 和 因变量与其他自变量回归残差 的散点图,可以在控制其他因素的影响后考察自变量与因变量的线性趋势。Y•[i] = residuals from regressing Y (the response variable) against all the independent variables except Xi,Xi•[i] = residuals from regressing Xi against the remaining independent variables.
Save…对话框:生成新的变量。本例生成标准化预测值、非标准化残差、标准化残差用于线性和方差齐性的诊断,生成Cook距离、杠杆值用于检测异常点。
- 预测值(Predictedvalues):非标准化预测值(Unstandardized,模型对因变量的院原始预测值)、标准化预测值(standardized,预测值用均值和标准差进行标准化,均数为0,标准差为1)、调整的预测值(Adjusted,不考虑当前个体拟合的模型计算的当前记录的预测值)、预测均值的标准误。
- 残差(Residuals),可保存各种残差,用于模型的诊断。包括未标准化残差、标准化残差、学生化残差、剔除残差、学生化剔除残差。
- 距离(Distance):Mahalanobis、Cook’s、leveragevalue。用于检测数据市场存在高杠杆点和强影响点。马氏距离和杠杆值用于检查数据在X空间是否异常(高杠杆点),杠杆值大于3倍平均杠杆值就应引起重视;库克距离的值越大对回归估计值影响越大。
- 影响力统计量:DfBeta(S)(意义为剔除某一观测值引起的回归系数的变化)、StandardizedDfBeta(S)、DfFit(Difference infit,意义为剔除某一观测值所引起预测值的变化)。以上4个统计量值越大越可能是强影响点,一般DfFit超过2可认为是强影响点。Covarianceratio(意义为剔除某一个体值的协方差阵与含有全部观测值的协方差阵的比率)。强影响点是指对统计结果影响较大的点,高杠杆点(X空间上的异常点)和离群点(Y空间上的异常点)都可能成为强影响点。
- 预测区间等。可提供预测值均值的可信区间和个体预测值的参考区间。
Options…对话框:可选择在逐步回归中的纳入和剔除标准,模型是否包含常数项,以及对缺失值的处理方法
(4)利用残差考察因变量与自变量的线性关系:Graphs>>Chart Bulider
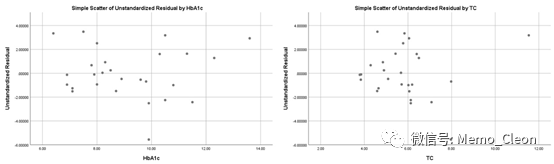
选择散点图/点图(Scatter/Dot),双击简单散点图(Simple Scatter),将要HbAc1拖入横坐标的X-Axis?框,将新生成的RES_1(非标准化残差)拖入纵坐标的Y-Axis?框,OK。同样,可实现TC对RES_1的散点图。
(5)高杠杆点和强影响点的考察:对新生成的变量COOl_1(库克距离)和LEV_1(杠杆值)进行降序排列。可使用Data>>Sort Cases…,然后选择要排序的变量进行降序排列;也可直接在要排序的列上单击右键,选择Sort Descending。也可以通过Data>>Select Cases…来直接寻找满足条件的记录。
结果与解读
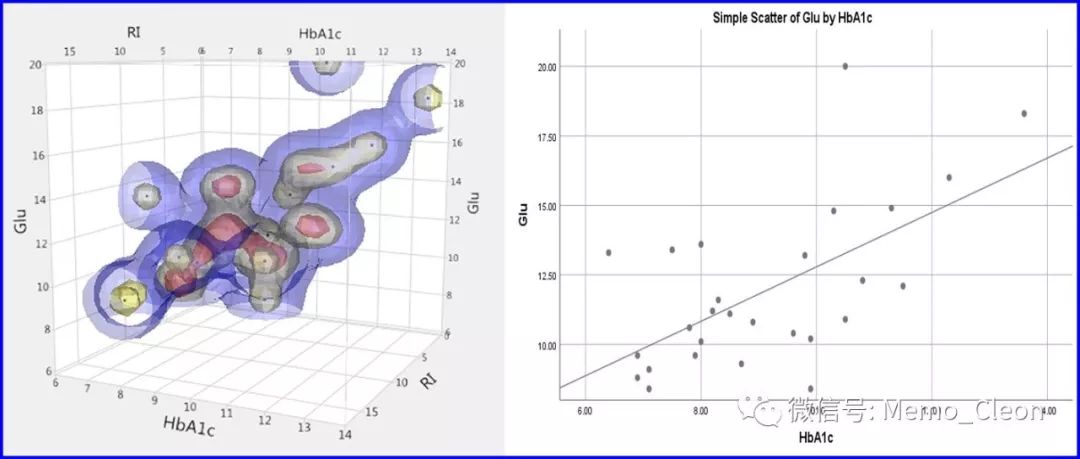
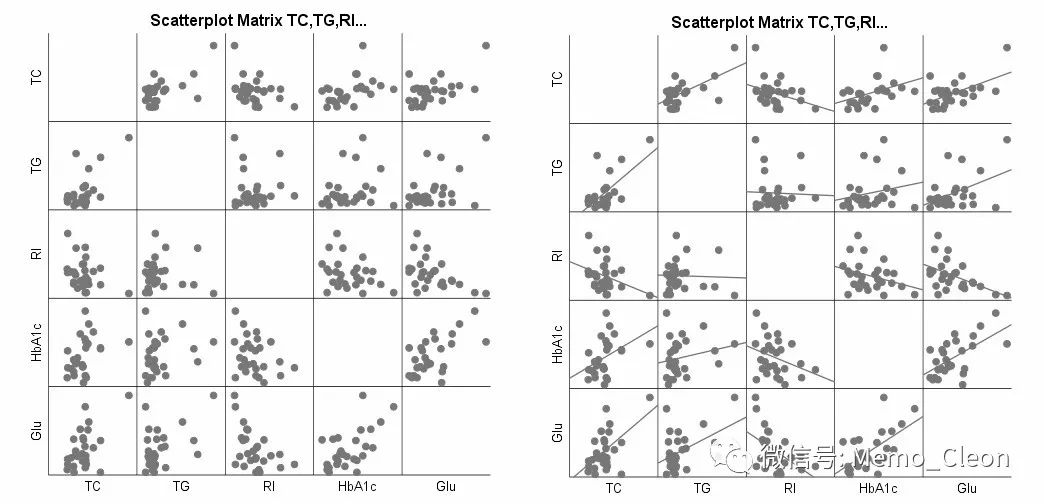
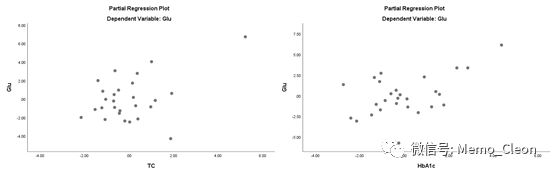
【1】线性趋势考察:右图是在左图的基础上添加了拟合线。可以看出4个变量与Glu基本成线性关系。
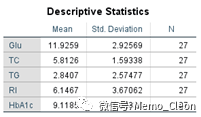
【2】描述统计量:显示各变量的均值、标准差及例数。
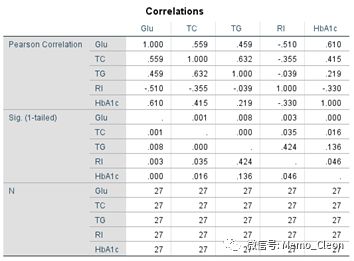
【3】相关系数:输出各变量间的Pearson相关系数和统计检验结果。【2】和【3】同为“统计量…“中“描述“的输出结果。 如果各自间的相关系数过大,提示有多重共线的可能。
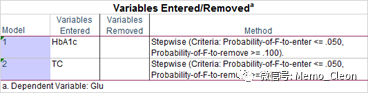
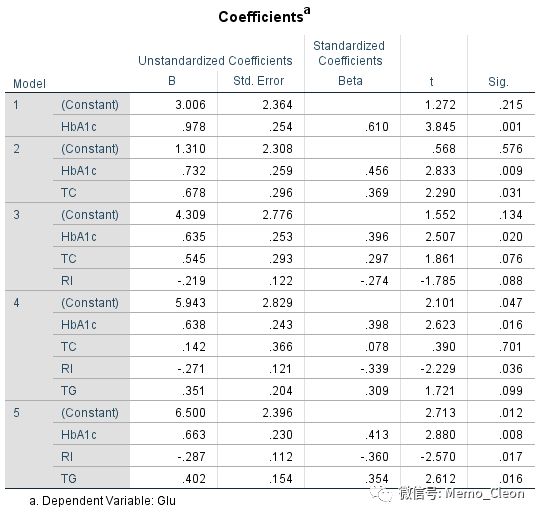
【4】模型纳入和剔除的变量:本例采用的是Stepwise,共建立过两个回归模型,纳入2各变量(HbAc1和TC),默认纳入标准P≤0.5,剔除标准≤0.1。
【5】模型概要:默认输出模型的一些拟合优度评价指标信息:复相关系数R,决定系数R2,校正决定系数R2adj以及剩余标准差(Std. Error of the Estimate),这些统计量及ANOVA检验表由统计量对话框中的“模型拟合”输出;同时本例在统计量对话框中还选择了R改变量、Durbin-Watson检验,在该表格中一并输出了这两个结果。
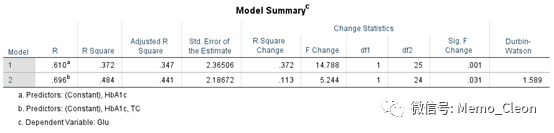
结果显示:最终的模型复相关系数R=0.696,所有自变量于Glu之间的回归关系比较密切;R2=0.484,Glu的总变异中,最终模型中2个自变量可以解释的变异占48.4%;与只纳入HbAc相比,校正决定系数R2adj在增大,剩余标准差减小,说明拟合效果越来越好。纳入新的变量后,R2的改变也有统计学意义。DW=1.589,查DW分布表,界值在1.240-1.556,DW=1.589>1.556,不存在相关性。Durbin-Watson取值0-4,DW=2表示自变量间不存在自相关(即相互独立),0<DW<2表示正相关,2<DW<4表示负相关。当然统计上给出的DW分布表是一个由自变量个数和样本量确定的范围,根据0<DW<下界值则存在自相关,上界值<DW<4表示残差间相互独立,DW在上下界值之间则不能确定,可参考https://en.m.wikipedia.org/wiki/Durbin–Watson_statistic.
【6】方差分析:输出回归模型检验结果,该表格与上一个表格(Model Summary)中默认输出的衡量模型拟合优劣的几个系数都是Statistics…对话框中Descriptives的输出结果。表明最终回归模型F=11.271,P<0.01,至少有一个自变量的回归系数不为0,回归模型有统计学意义。
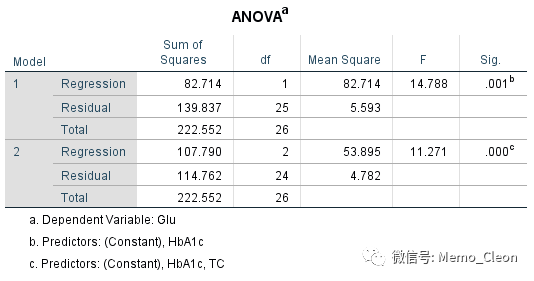
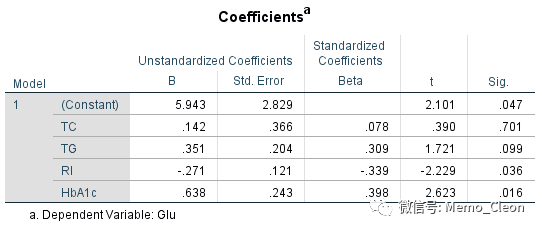
【7】系数:输出模型的偏回归系数的估计值,包括非标准系数,标准化系数、以及各个偏回归系数是否为0(是否与因变量存在线性相关)的t检验。由于本例还同时选择了95%CI、部分相关和偏相关、共线性诊断,结果在该表格中一并输出。
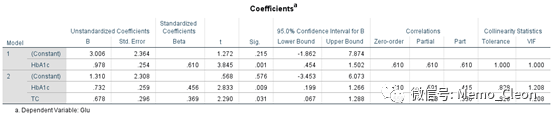
纳入模型的各自变量偏回归系数均不为0(PHbAc1=0.009<0.05;PTC=0.031<0.05),最终回归模型为:Glu=1.310+0.732HbAc1+0.678TC。糖化血红蛋白(HbAc1)每增加1%,血糖(Glu)平均下降0.732mmol/L;总胆固醇(TC)每增加1mmol/L,血糖(Glu)平均下降0.678mmol/L。
标准化回归系数Beta去掉了不同自变量单位不同的影响,是利用标准化数据标计算而来,标准化数据=(原始数据-均值)/标准差。标准化回归方程常数项为0,标准化回归系数Beta=回归系数β*(自变量X的标准差/因变量Y的标准差),在有统计学意义的前提下,标准化回归系数的绝对值越大,对应自变量对因变量Y的影响越大。其意为固定其他自变量,自变量每改变1个标准差,因变量改变的标准差个数。标准化后的变量均值为0,标准差为1,常数项为0。该例Beta:HbAc1=0.456>0.369=TC,表明糖化血红蛋白(HbAc1)对血糖(Glu)的影响大于总胆固醇(TC)对血糖(Glu)的影响。
在解释自变量对回归的贡献时,只查看回归系数往往是不够的,相关关系也需要一并考虑。相关系数部分提供了0介相关、偏相关和部分相关系数。
0介相关结果等同Pearson相关,与描述(Descriptives)的输出的相关系数表格结果一致。
偏相关(Partial Correlation)系数是自变量和因变量均剔除其他自变量影响后的相关系数,等同于自变量对其他自变量的回归残差与因变量对其他自变量的回归残差之间的相关系数。偏回归相关系数的平方则表示,去掉其他自变量的影响,自变量可解释的因变量变异的比例【The partial correlation coefficient removes the linear effects of other predictors from both the predictor and the response. This measure equals the correlation between the residuals from regressing the predictor on the other predictors and the residuals from regressing the response on the other predictors. The squared partial correlation corresponds to the proportion of the variance explained relative to the residual variance of the response remaining after removing the effects of the other variables】。本例控制TC的对HbAc1和Glu的影响,HbAc1可以解释(0.501)2=25.1%的血糖变异;控制HbAc1的对TC和Glu的影响,同样TC可解释17.9%的血糖变异。
部分相关(Part Correlation)是自变量剔除其他自变量的影响后与因变量整体的相关关系,其平方代表的是自变量剔除其他自变量的影响后可解释的总变异的比例【The correlation between the response and the residuals from regressing a predictor on the other predictors is the part correlation. Squaring this value yields a measure of the proportion of variance explained relative to the total variance of response】。本例去除TC对HbAc1的影响,HbAc1剩余部分可以解释血糖17.2%的变异;去除HbAc1对TC的影响,TC剩余部分可以解释血糖11.3%的变异。
共线性统计量:提供了容差(Tolerance)和方差膨胀因子(VIF),一般容差不小于0.1,VIF(容差的倒数)不大于10可说明自变量不存在共线的情况,本例两个自变量Tolerance=0.828,VIF=1.208,可以认为不存在共线的情况。
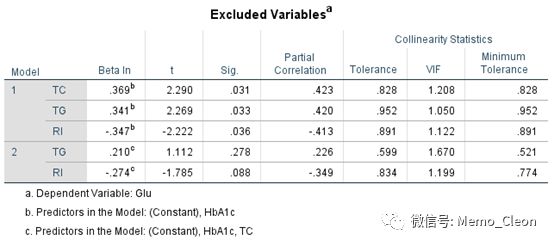
【8】排除的变量:将这些变量进一步纳入现有模型中后的输出结果。TG和RI纳入最终的模型,偏回归系数检验均无统计学意义。
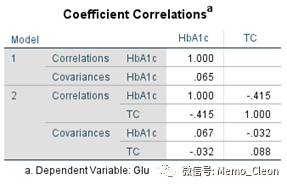
【9】系数相关:输出相关和协方差矩阵,是各变量间的相关系数和协方差,相关系数和相关系数表格【3】结果一致;协方差表示各个维度偏离其均值的程度,协方差矩阵用于衡量各个变量之间的紧密程度。

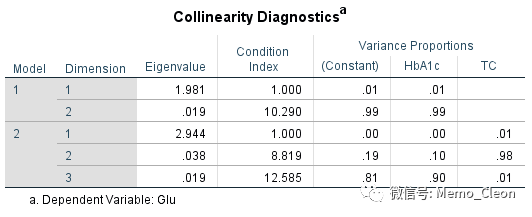
【10】共线性诊断:除了在系数表中输出共线性诊断统计量Tolerance和VIF,共线性诊断还提供了特征根(Elgenvalue)、条件指数(Condition Index)及变异构成(Variance Proportions)。主成分特征根意义为该变量被引入后,可以解释原始变量的个数。如果几个主成分的特征根接近0,则表明自变量高度关联,数据值较小的改变会导致偏回归系数发生较大的变化。条件指数是最大特征根与每个连续特征根比值的平方根,比值>15提示可能存在共线性的问题,>30则表明存在共线性。变异构成(方差比例)是回归模型中各项(包括常数项)变异能被主成分解释的比例,如某主成分对两个或两个以上的自变量贡献均较大(如>0.5),则提示这几个变量存在一定的共线性。
本例几个指标结果提示最终进入模型的两个自变量基本不存在共线性。
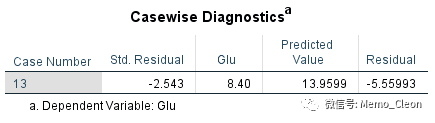
【11】个案诊断:Statistics…对话框中个案诊断(Casewise Diagnostics)的输出结果,主要用来查看有无离群值。在个案诊断中可以有两种输出形式,一种是显示所有记录的编号、标准残差、观测值、期望值和残差,另外一种只显示离群值的基本信息,离群值默认以超过3个标准差的残差为标准。本例无离群点,为显示该功能及输出样式,将异常点改为超过2个标准差的残差,结果显示如下:第13条记录满足此条件被显示出来。
【12】残差统计量:Durbin-Watson检验输出的预测值、残差、标准预测值及标准残差,该分析输出的检验统计量DW值在模型概要表中显示。马氏距离、库克距离及杠杆值得保存可输出更多的残差统计量。
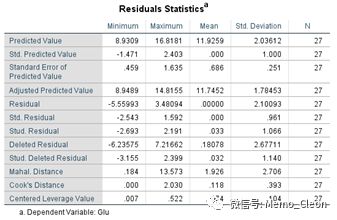
【13】残差正态分布考察:正方图和P-P显示残差基本满足正态分布。
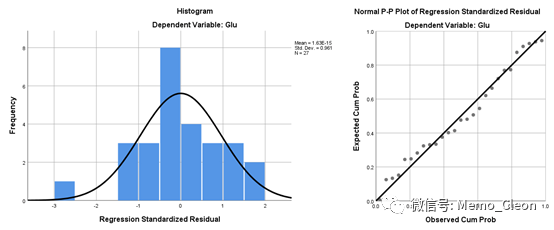
【14】残差分析:正常情况下,残差服从均数为0,方差为δ2的正态分布,而标准化残差服从均数为0,方差为1 的正态分布。①离群值考察:超过3个标准差的残差为离群值,结果可以在残差图上直观的显示出来,当然在个案分析中也有输出;②方差齐性考察:以标准化预测值对标准残差作散点图,此图可在“绘图”对话框中质结构建,也可以先在“保存”对话框中保存需要的两个变量,然后用图形构建器构建。也可以构建各个自变量对标准残差作散点图。如果标准化残差随机较均匀的散布在0横线上下两侧,可认为方差基本相等,但如果标准残差随标准预测值增大出现扩散或收敛,则方差可能不齐。③线性关系考察:如果标准残差呈现一定的曲线变化,则因变量与自变量可能不是线性关系或者残差不独立。
本例无离群值,但可能存在一高杠杆点;不论因变量预测值如何变化,标准化残差随机分布在残差为0的横线上下,不存在异常点,基本保持稳定,可认为方差齐性;HbAc1和TC的残差图显示,残差基本随机分布在0水平线的两侧,没有明显偏正或偏负的趋势,说明HbAc1、TC和Glu呈线性关系。但是HbAc1的残差散点图分布不是十分理想,隐约有一个先下后上的趋势。
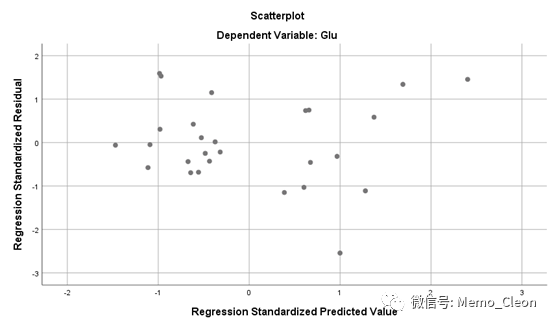
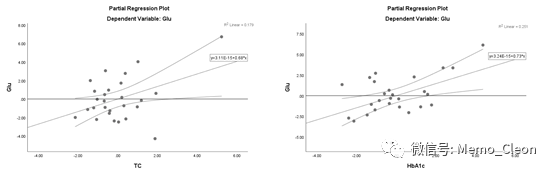
【15】偏残差图*再次考察线性趋势:普通散点图虽然可以考察线性趋势,但当存在混杂因素的印象时,可能会出现一些偏差。偏残差图是在校正了其他因素的影响后自变量与因变量的关系,能够更准确的判断自变量与因变量是否为线性。TC和HbAc1的偏残差图如下:
偏残差图添加拟合线、95%置信曲线及Y残差=0后如下图:TC和HbAc1的95%的置信曲线均跨过水平线,效应显著,均大致呈线性,即两个自变量在去除其他因素的影响后与Glu均呈直线关系,更有利于解释变异。
【16】异常点考察:①离群点(因变量角度的异常值):一般以超过3个标准差的残差为标准,【11】个案诊断表并未显示,表明本例无离群值。【11】表只是为了更好地演示将标准改为2个标准差而出现的表;②高杠杆点(自变量角度异常点):杠杆值一般<0.2,>0.5很可能是强杠杆点,0.2-0.5之间应引起怀疑。杠杆值降序排序显示个案号为25的记录LEV=0.52,可能为强杠杆点;③强影响点:库克距离的值越大对回归估计值影响越大,库克距离>0.5,可能为强影响点,>1严重怀疑是强影响点。库克距离值降序排序显示个案号为25的记录COO=2.03,可能为强影响点。
出现强影响点,应充分考虑该记录产生的原因,是人为的录入错误,还是该记录跟其他记录的纳入标准明显不一样,如此,则需要删除该记录。如果都不是,或者尝试增加样本量,或者进行稳健回归,比如加权最小二乘法,可以先用普通最小二乘法做多重线性回归,将残差存为新变量,然后把这个残差进行加权。
后记:
(1)当然,研究者根据专业知识和经验,判定总胆固醇、甘油三酯、胰岛素和糖化血红蛋白都会对血糖有影响,可以将所有自变量直接纳入模型而不是筛选自变量。此时变量筛选办法为Enter,最终回归方程为:Glu=5.943+0.142TC+0.351TG-0.271RI+0.638HbAc1。回归系数的解释及其他结果可参照逐步回归结果。
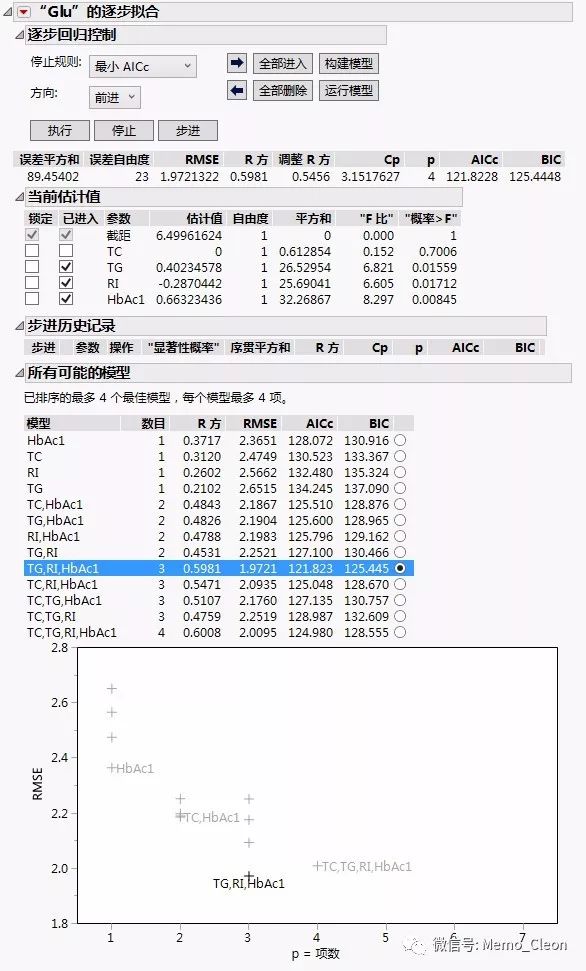
(2)多元线性回归方程默认的变量纳入和剔除标准分别为P<0.05和P<0.1,这个标准可以在Options…对话框中进行修改,本例样本量不大,α值可以适当放宽,但要α入≤α出。如本例纳入和剔除标准分别改为0.1和0.15,纳入变量为TG、RI和HbAc1,最终回归方程变为::Glu=6.500+0.402TG-0.287RI+0.663HbAc1。
实际上这个结果与最优子集筛选结果一致。最优子集选择在SPSS中可以通过自动建模(Automatic Linear modeling)实现
Analyze>>Regression>> Automatic Linear modeling…
Fields>>Target:Glu;Predictors:TC、TG、RI、HbAc1;
Build Options>>Objectives:Creat astandard model;
>>Basics:本例使用原始数据不进行处理,去掉自动准备数据的复选框;
>>Model Selection:模型选择方法:最优子集;
其他项为默认选项
根据AICC标准选择的结果如下:
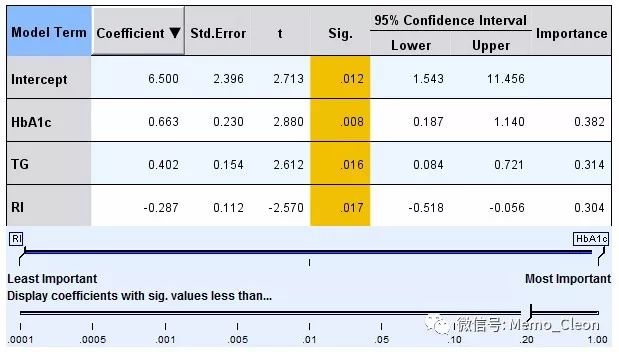
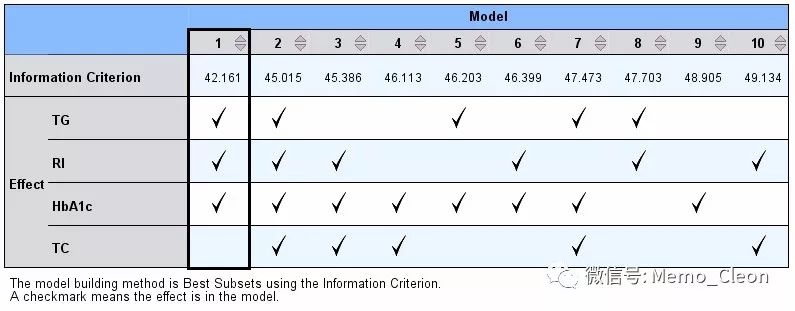
当然,SPSS中默认进行对数据进行前处理,比如去掉离群值等,还有诸多其他一些模型拟合信息,本例不再做演示。JMP给出的所有可能模型结果如下。当模型纳入TG、RI和HbAc1时,R2最大,剩余标准差最小,AIC和BIC值最小,拟合的模型最优,各变量系数与SPSS结果完全一致。
(3)关于交互作用的一些探讨。
模型中纳入了TG(甘油三酯)、RI(胰岛素)以及HbAc1(糖化血红蛋白),专业上考虑糖化血红蛋白的作用大小可能与胰岛素的取值有关,即两者可能有交互作用,可以先构建两者的乘积项,然后对其进行检验。
构建交互项:Transform>>Computer Variable…
Target Variable:RHb(新构建的乘积项名称)
Numeric Expression:RI*HbAc1
回归分析:Analyze>>Regression>>Linear…
Dependent(因变量):选入Glu;
Independent(自变量):选入TG、RI、HbAc1、RHb;
变量筛选方法(Method):Enter
经检验,模型F=13.862,P<0.01,模型有统计学意义,回归方程Glu=-0.790+0.365TG+1.227RI+1.510HbAc1-0.179RHb。交互作用RHb显著(P=0.006),我们可能会立即得出这样一个结论:糖尿病患者体内胰岛素对血糖的影响依赖于糖化血红蛋白的含量。
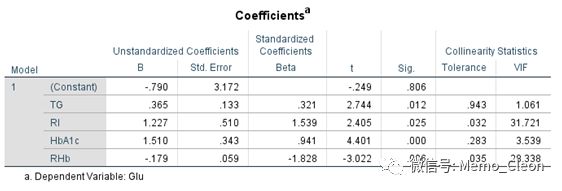
但是我们会马上发现这个模型也有问题!!是的,胰岛素每增加1uU/ml,血糖升高1.227mmol/L,这显然与实际不符,专业上胰岛素与血糖呈负相关,所以在构建的含有交互项的多重线性回归模型很可能存在多重共线的问题,统计学检验也证实了这一点(RI和交互项RHb的Tolerance均<0.1,VIF均>10)。
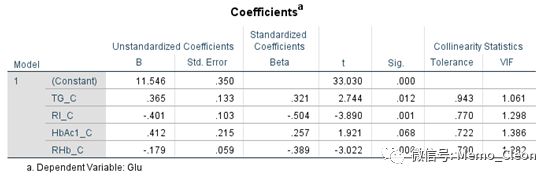
对此问题,经管之家论坛有人给出了如下解决方案(https://bbs.pinggu.org/thread-6379009-1-1.html):交互项的加入可能导致多重共线,多重共线性可能导致交互项结果估计不准确。在交互项中解决多重共线性的一个方法是:变量去中心化后再回归,即将自变量减去他们的均值再回归,主要结果如下:
END
来自外部的引用