

生存分析是分析生存时间的统计学方法,其因变量需要用生存时间和结局状态两个变量来刻画,可以将终点事件是否发生以及发生终点事件所经历的时间相结合起来。生存分析的主要内容有生存时间的分布描述、生存时间分布的组间比较以及生存时间分布的影响因子的效果评估。在SPSS中其分析过程存在于菜单"分析(Analyze)>>生存分析(Survival)"中。
本次笔记内容:
- 几个概念
- 寿命表法
- Kaplan-Meier法
- Cox比例风险模型回归
- 含时依协变量的Cox回归
【1】几个概念
失效事件(Failure Event):常被简称为事件,研究者规定的终点结局,医学研究中可以是患者死亡,也可以是疾病的发生、某种治疗的反应、疾病的复发等。与之对应的起始事件可以是疾病的确诊、某种治疗的开始等。
生存时间(Survival Time):常用t表示,从规定的起始事件开始到失效事件出现所持续的时间。对于失访者,是失访前最后一次随访的时间。
删失/截尾(Censoring):由于某些原因在随访中并没有观测到失效事件而不知道确切的生存时间,此部分数据即删失数据。常见原因有失访、患者退出试验、事件发生是由于非研究性疾病(如研究病人发生脑卒中后的生存时间,结果病人因为车祸死亡)、研究结束时研究对象仍未发生失效事件。删失数据的生存时间为起始事件到截尾点所经历的时间。
生存函数(Survival Function)与风险函数(Hazard Function):生存函数也称为积累生存函数/概率(Cumulative Survival Function)或生存率,符号S(t),表示观察对象生存时间越过时间点t的概率,t=0时生存函数取值为1,随时间延长生存函数逐渐减小。以生存时间为横轴、生存函数为纵轴连成的曲线即为生存曲线。风险函数表示生存时间达到t后瞬时发生失效事件的概率,用h(t)表示,h(t)=f(t)/S(t)。其中f(t)为概率密度函数(Probability Density Function),f(t)是F(t)的导数。F(t)为积累分布函数(Cumulative Distribution Function),F(t)=1-S(t),表示生存时间未超过时间点t的概率。累积风险函数H(t)=-logS(t)。本人数学很差,概率密度和积累分布的关系类似于速度与位移的关系。
中位生存时间(Median Survival Time)/平均生存时间(Mean Survival Time):中位生存时间又称半数生存期,表示恰好一半个体未发生失效事件的时间,生存曲线上纵轴50%对应的时间。平均生存时间则表示生存曲线下的面积。
不同的方法有不同适应条件,本笔记仅用于SPSS的操作演示及结果解读,各种分析方法使用同一份数据,数据来源于孙振球主编的《医学统计学》第三版。数据是一项关于HIV阳性患者的生存时间的临床随访研究,研究对象是于2002年1月1日至2004年12月31日期间在某市确诊为HIV阳性患者。随访这些对象直至死于AIDS,研究截止日期为2008年12月31日。数据录入:研究对象生存时间(Time),性别(Gender=0为女,Gender=01为男),年龄(Age,岁),是否用药(Drug=1为用药,0为不用),事件状态(Status=1为死亡,0为删失)。
【2】寿命表法
单因素生存分析分析方法,可用于的生存率估计与比较。更倾向于回答生存时间内的生存率如何。适用于样本较大的生存资料,或者数据已经按若干时段的频数形式表示的数据。
分析(Analyze)>>生存分析(Survival)>>寿命表(Life Tables…)
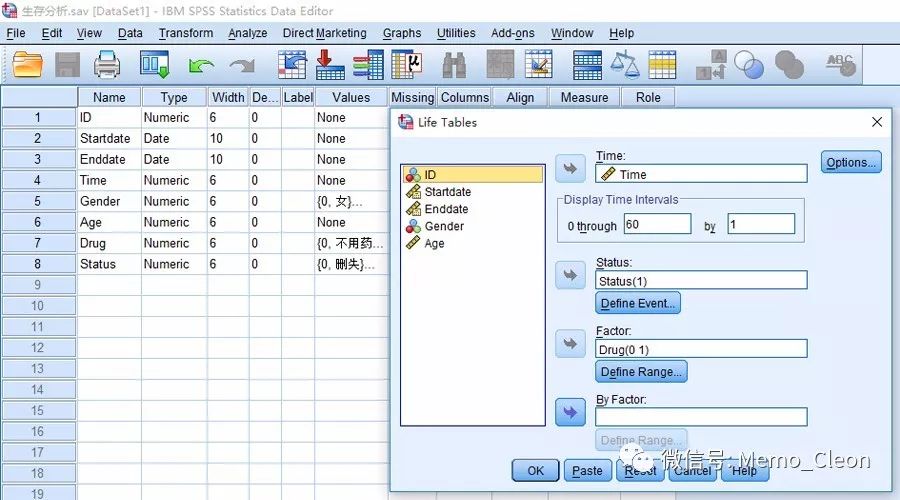
- 生存时间(Time):选入生存时间变量,本例为Time
- 显示时间间隔(Display Time Intervals):0到(0 through)[ ] 步长(by)[ ]
定义寿命表时间区间的终点和长度。by前为最后一个区间的开始时间,本例研究自2002年1月1日开始,截止日期为2008年12月31日,理论上最长生存时间是7年(84个月),按年可以分为7个区间,按月可以分为84个区间。实际上查看数据,本例生存时间最长为61个月。应注意寿命表分析的第一个区间的起始时间为0,若分为61个区间则最后一个区间的起始时间为60。by后为区间的组距,本例可按每月统计数据进行时间间隔的设置,设为1。
- 状态(Status):生存结局状态变量,是失效事件还是删失数据,本例选入Status。点击定义时间按钮(Define Event…)定义终点事件发生的值,单值(Single Value)处填入表示事件发生的值,本例Status=1时表示HIV患者死亡。也可以用某范围内的数值表示事件。
- 因素(Factor):定义分组变量,结果中用一阶控制(First-order Controls)来表示该因素的各水平情况。本研究想比较下用药与不用药的生存率是否有差别,可将变量Drug选入。点击定义组距按钮(Define Range…)定义组别的最小值和最大值,本例Drug=0表示不用药,Drug=1表示用药,因此最小值为0,最大值为1。
- 按因素(By Factor):分层变量,一般选入混杂因素。如在因素(Factor)中选入了分组变量,此处的入选变量在结果中用二阶控制(Second-order Controls)来表示其各水平情况。如果在因素(Factor)中未选入分组变量,此处的入选变量在结果中用一阶控制(First-order Controls)来表示其各水平情况。实际上当因素(Factor)和按因素(By Factor)只用其中一个,如选入相同的变量,效果是等同的。
- 选项按钮(Options…)寿命表(Life Tables),默认选项,寿命表法估计生存率。
作图(Plot):生存函数曲线(Survival)、对数生存函数曲线(Log Survival )、 风险函数散点图(Hazard)、密度函数散点图(Density)、1-生存函数曲线(One minus survival)。本例选生存函数曲线。
第一因素各水平的比较(Compare levels of First Factor):用于组间各水平的比较。默认不进行比较(None);整体比较(Overall)是按分组因素进行采用Wilcoxon(Gehan)法对各水平进行整体比较,本例选该项;成对比较( Pairwise)则是进行分组变量间的两两比较,本例只有Drug只有两个水平,因此进行整体分析和成对分析的结果是一致的。Compare Levels of First Factor: If you have a first-order control variable, you can select one of the alternatives in this group to perform the Wilcoxon (Gehan) test, which compares the survival of subgroups. Tests are performed on the first-order factor. If you have defined a second-order factor, tests are performed for each level of the second-order variable.
结果及其解读:
(1)寿命表
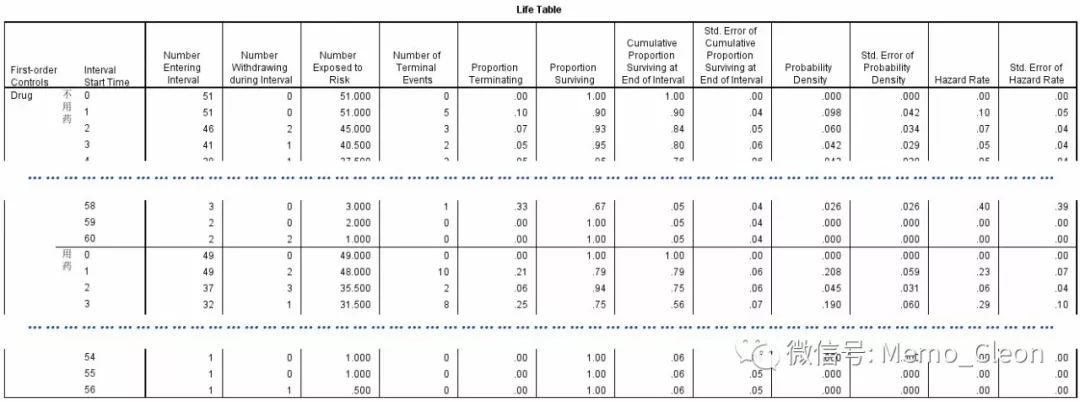
- First-order Controls(一阶控制因素):通过分组因素(Factor)/分层因素(By Factor)文本框确定的控制因素
- Interval Start Time(区间期初时间):组段开始时间,注意寿命表开始的第一个区间是从0开始
- Number Entering Interval(区间期初例数):组段开始时计入的例数
- Number Withdrawing during Interval(区间内退出例数):组段内退出的例数,即发生删失/截尾的人数
- Number Exposed to Risk(暴露于危险因素的例数):等于区间期初例数-区间退出例数的一半,相当于校正的例数。此处是寿命表法与Kaplan-Meier不同的地方。
- Number of Terminal Events(发生终点事件的例数):发生失效事件的人数
- Proportion Terminating(发生终点事件的比例):等于发生终点事件的例数/暴露于危险因素的例数。以区间期初时间2为例,其值等于3/45=0.07
- Proportion Surviving(生存比例):1-发生终点事件的比例,以区间期初时间2为例,其值等1-0.07=0.93
- Cumulative Proportion Surviving End of Interval(区间期末累积生存比例):本组段生存函数估计值,等于生存比率累积相乘,以区间期初时间2为例,其值等于1×0.90×0.93=0.84
- Probability Density(概率密度):即概率的密度,累积分布函数的导数,An estimate of the probability of experiencing the terminal event during the interval
- Std.Error of Probability Density(概率密度标准误)
- Hazard Rate(风险率):风险函数,生存时间达到t后的瞬时发生失效事件的概率。An estimate of the risk of experiencing the terminal event during the interval, conditional upon surviving to the start of the interval.
- Std.Error of Hazard Rate(风险率标准误)
(2)中位生存时间。用药和不用药的中位生存时间分别为5.09个月和11.41个月,即用药死亡人数达到一半的时间是5.09个月,不用药死亡人数达到一半的时间是11.41个月。【如果这些数据是临床试验结果,那么这个药物不是一个好的治疗药物】

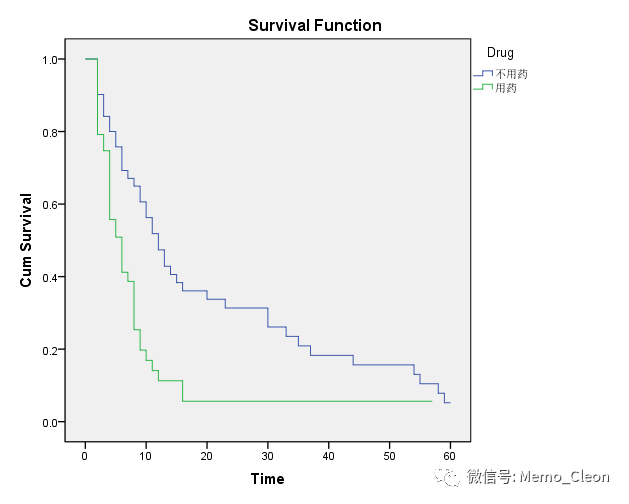
(3)生存曲线。横坐标为生存时间,纵坐标为累积生存函数。横坐标上每个点代表了经过这个时间点仍然存活的概率。
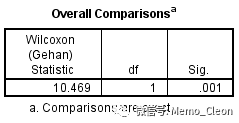
(4)控制变量组间比较。结果显示,用药和非用药的HIV患者生存率差别有明显的统计学意义(D=10.469,P=0.001<0.05)。
Comparisons for Control Variable: Drug
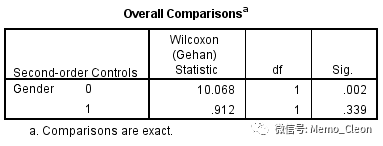
如分组变量文本框不选入变量,而分层变量选入Drug,结果跟上面是一样的。若分组变量选入Drug,分层变量选入性别Gender,则上述所有结果按如下形式输出:直接输出男和女两种性别下,各自用药和不用药的比较,其并不考虑分层因素性别对生存时间的影响。以组间比较为例,结果如下:女患者用药和不用药的生存率是不同的(P=0.002),但男患者用药和不用药的生存率差别无统计学意义(P=0.339)
【3】Kaplan-Meier法,也称乘积极限法
单因素生存分析方法,可用生存率的估计、生存率比较及较影响因素分析。倾向于给与某种治疗措施后生存时间的变化情况。大小样本均适用,除比较因素外要求其他混杂因素组间均衡。当用分层变量控制混杂因素时,分层因素只限一个,且须是分类变量。
分析(Analyze)>>生存分析(Survival)>>Kaplan-Meier…
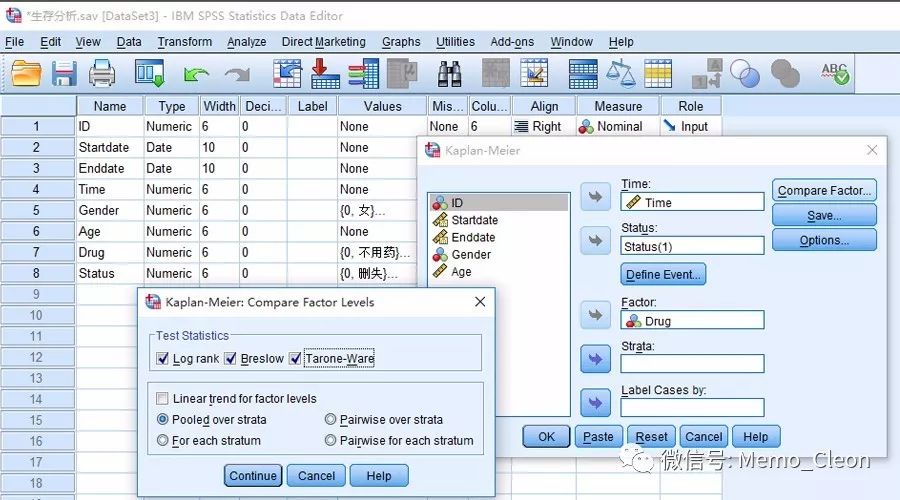
- 生存时间(Time):选入生存时间变量,本例为Time
- 状态(Status):生存结局状态变量,是失效事件还是删失数据,本例选入Status。点击定义时间按钮(Define Event…)定义终点事件发生的值,单值(Single Value)处填入表示事件发生的值,本例Status=1时表示HIV患者死亡。
- 因素(Factor):分组变量,本例选入变量Drug。
- 层(Strata):分层变量,用于分层分析,控制混杂因素。若选入变量,结果将按该变量的各水平分别输出。
- 个案标签(Label Cases by):选入变量后在结果的生存表中将显示个案的该变量内容
- 因素比较(Compare Factor…)检验统计量(Test Statistics):对数秩(Log rank)、Breslow、Tarone-Ware。本例三种方法均选入进行两组生存率的比较。
因素水平的线性趋势(Linear trend for factor levels):用于分析风险率随分组等级的变化而变化的趋势,一般用于分组因素为有序多分类的等级资料的线性分析,本例分组因素只有2水平,必成线性趋势,没有什么实际意义。
寿命表法中的分层仅是按分层变量的不同水平进行分层输出,并不考虑其对生存时间的影响。与寿命表的处理方法不同,Kaplan-Meier法是控制分层变量后研究分组因素对生存时间的影响,输出的是校正后的结果。选入分层变量后,分组因素不同水平间生存函数的比较会因分层变量的处理方式不同而按不同的形式输出,具体处理方式及输出形式如下,输出结果见结果及解读部分。
在层上整体比较因素各水平(Pooled over strata):控制分层因素后,对分组因素进行整体比较。是对没有分层因素结果的校正。只有一个统计量。
分层整体比较(For each stratum):按分层变量的不同水平分层输出,每层分别对分组因素的各水平进行整体比较。
在层上成对比较因素水平(Pairwise over strata):控制分层因素后,对分组因素的各水平进行两两比较。线性趋势检验不进行两两比较。
分层成对比较因素水平(Pairwise for each strata):按分层因素的不同水平分层输出,每层分别对分组因素的各水平进行两两比较。线性趋势检验不进行两两比较。
- 保存(Save…):可以保存新变量,生存函数(Survival )、生存函数标准误(Standard error of survival)、危险函数(Hazard)、累积事件(Cumulative events)
- 选项按钮(Options…)统计量:生存分析表(Survival table)、均值和中位数生存时间(Mean and median survival)、四分位数(Quartiles)
- 作图(Plot):生存曲线(Survival)、1-生存率曲线(One minus survival)、 风险函数曲线(Hazard)、对数生存曲线(Log Survival )。本例选生存曲线。
结果及解读:
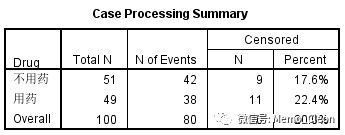
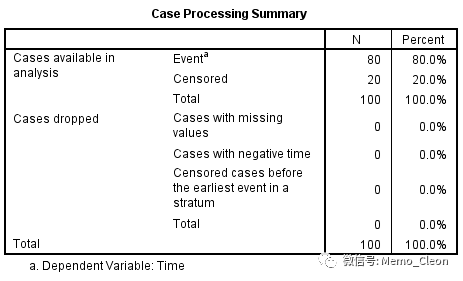
(1)个案处理概要表:各组生存情况总结,显示总例数、事件数及删失比例。本例不用药组51例,发生失效事件(死亡)42例,删失9例;用药组49例,发生失效事件(死亡)38例,删失11例。总共100例,发生事件80例,删失20例。
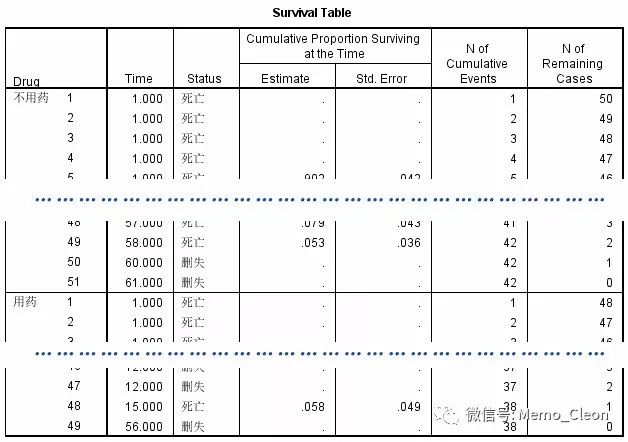
(2)生存表:给出生存时间、生存结局、积累生存比例、累积事件数和剩余个案数等信息。本案指定了分组变量Drug,结果按Drug的不同水平进行输出。删失数据无法估算生存函数、标准误等信息,删失数据也不算入累积事件数,但该时间点后的剩余个案数需要减去删失数。本例具体情况见下表。
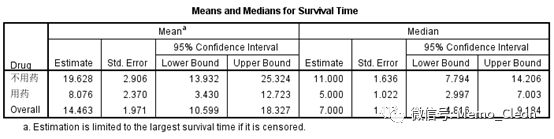
(3)生存表的平均值和中位值:给出了各组生存时间均值和中位值,及其相应的标准误和95%CI。该表考虑了删失情况后校正值。本例不用药组均值19.628,中位值11;用药组均值8.076,中位值5;总体均值14.463,中位值7。
(4)整体比较:通过统计学检验给出了生存函数的组间比较,本例3种检验方法均有统计学意义,表明用药和不用药组生存函数的不同是由于不同的治疗方式造成的。
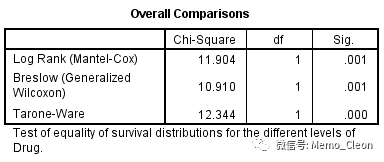
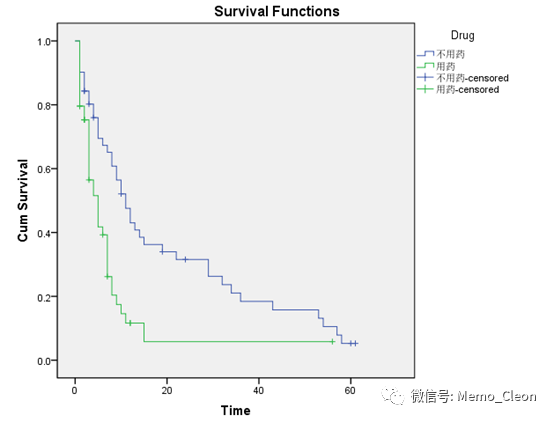
(5)生存曲线:从图形上看,本例不用药组患者的存活状况要比用药组更好。这种差异是抽样误差造成的还是不同的治疗方式造成的,还需要看前面的统计学检验。
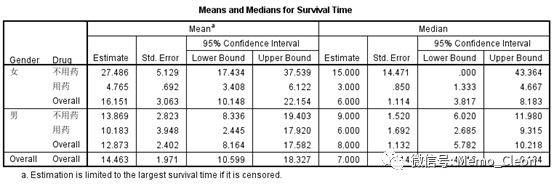
本例未选入分层变量,如选入分层变量后,除整体比较表外,上述其他各表将均按分层变量的不同水平分别输出。以生存时间均值和中位值表为例,如分层变量选入Gender,结果如下
整体比较结果会因分层变量的处理方式不同而按不同的形式输出,以Gender为分层变量为例,具体处理方式及相应的输出形式如下。需要说明的是,因素水平的线性趋势检验用于有序多分类的等级资料的检验,如结果有统计学意义,可以表述为,随着(因素各水平)的增加/递减,生存率呈线性递增/递减。本例分组因素只有2水平:用药和不用药,也不是等级资料,因为只有2水平,结果肯定呈线性,线性趋势检验实际上并没有什么实际意义,为更好的演示其输出形式,各种处理方式及对应的输出结果如下:
- 在层上整体比较因素各水平(Pooled over strata)。默认的选项,控制分层因素Gender后,对分组因素进行整体比较。
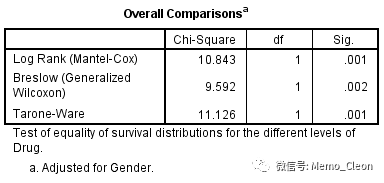
- 因素水平的线性趋势(Linear trend for factor levels)
- 在层上整体比较因素各水平(Pooled over strata)
输出的是线性趋势的3种统计检验结果(本例分组因素只有2水平,仅为演示无实际意义)。
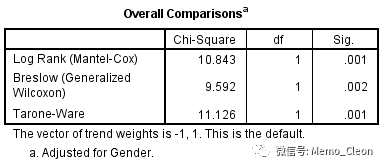
- 分层整体比较(For each stratum):按分层变量的不同水平分层输出结果,每层分别对分组因素的各水平进行整体比较
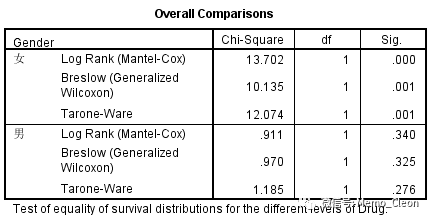
- 因素水平的线性趋势(Linear trend for factor levels)
- 分层整体比较(For each stratum)
表格上方按分层变量不同水平(女和男)输出两组的生存函数的整体比较结果,最下方是校正分层变量后线性趋势的3种统计检验结果(本例分组因素只有2水平,仅为演示无实际意义)。
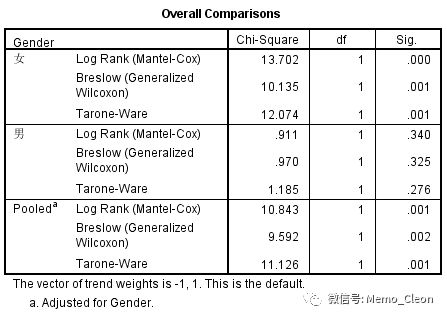
- 在层上成对比较因素水平(Pairwise over strata):控制分层因素后,对分组因素的各水平进行两两比较。线性趋势检验不进行两两比较。本例只有两组,其结果跟整体比较时一致的。
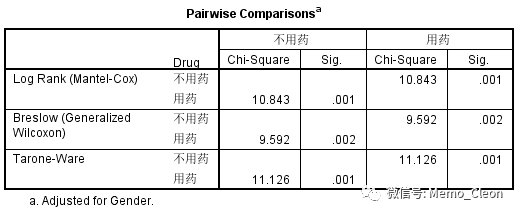
- 分层成对比较因素水平(Pairwise for each strata):按分层因素的不同水平分层输出,每层分别对分组因素的各水平进行两两比较。线性趋势检验不进行两两比较。
【4】Cox比例风险模型回归
多因素分析生存分析方法,可用于多因素的生存率估计、比较和影响因素分析。Cox回归模型要求满足比例风险的前提条件,在进行Cox回归前需进行比例分线性的检验。样本含量要求同logistic回归类似,要求至少10倍的自变量个数。
Cox比例风险回归模型的基本形式为:将某时点t个体出现失效事件的风险分为两部分:h0(t)和h(t,X)。第i个影响因素X使风险函数从h0(t)增加exp(βiXi)而成为h0(t)*exp(βiXi)。多个因素同时影响的模型为:
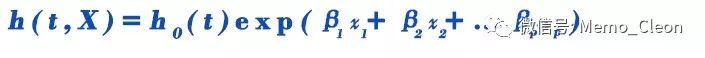
其中h(t,X)表示个体在协变量X(X=X1,X2…Xp)的作用下在时刻t的风险函数(风险率,瞬时事件发生率)。h0(t)为基准风险函数,是所有协变量取值为0时的风险函数。β为Cox回归模型的系数,是一组待估的回归参数,βp>0时X取值越大代表风险越大,βp<0时X取值越大代表风险越小,βp=0时X取值对风险函数无影响。exp(β)为预后指数,其值越大,风险函数h(t,X)越大,预后越差。
两个个体风险函数之比称为风险比(hazard ratio,HR),HR=暴露组的风险函数hi(t)/非暴露组的风险函数hk(t)。进一步的公式推导可得出:
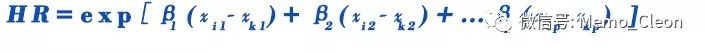
该比值与h0(t)无关,在时间上为常数,即模型中协变量效应不随时间变化而改变。通俗点讲,不论基准风险如何,在任何时间点上存在某一暴露的个体相对不存在该暴露的个体发生事件的风险是恒定的,也即两组人群在任何时间点上发生事件的风险比例是恒定的,护着解释为某一暴露在所有时间里对发生事件的作用都是相同的,这就是所谓的Cox回归模型的比例风险性(PH)假定。在0-1变量的Cox模型中,0组的风险函数=h(t,X=0)=h0(t),即基准风险函数,1组的风险函数=h(t,X=1)=h1(t)=h0(t)exp(β),由此可得h(t)/h0(t)=exp(β),即两组风险函数之比在时间上是常数,或两组风险函数成比例。
Cox回归最重要的前提条件是假定风险比为固定值,当PH不满足时,可将不呈比例关系的协变量作为分层变量,然后再将剩余变量进行Cox回归分析;第二种方法是采用时依协变量进行分段Cox回归;第三种方法是采用参数回归模型替代Cox回归模型。
注意风险比与风险率(Hazard Rate)的区别,风险率即风险函数指危险率函数、条件死亡率、瞬时死亡率。
HR与RR(相对危险比):不同于RR,HR包含时间因素在内,也就是说包含了时间效应的RR就是HR。生存资料中RR考虑了终点事件的差异,而HR不仅考虑了终点事件的有无,还考虑了到达终点所用的时间及截尾数据。在Cox回归中对exp(β)的解释实际上是跟RR一致的:自变量每增加一个单位,发病风险比原水平增加exp(β)倍。因此在许多教材中两者是混用的。
Cox比例风险模型回归SPSS操作及解读:
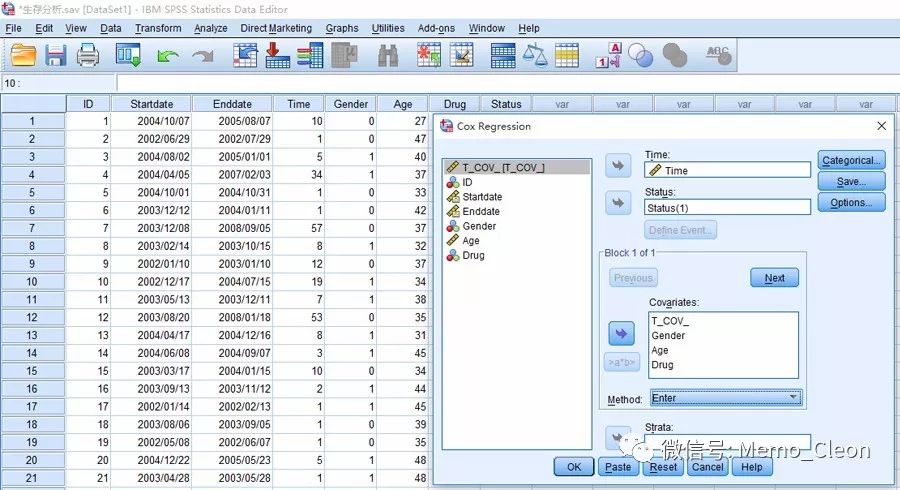
分析(Analyze)>>生存分析(Survival)>>Cox Regression……
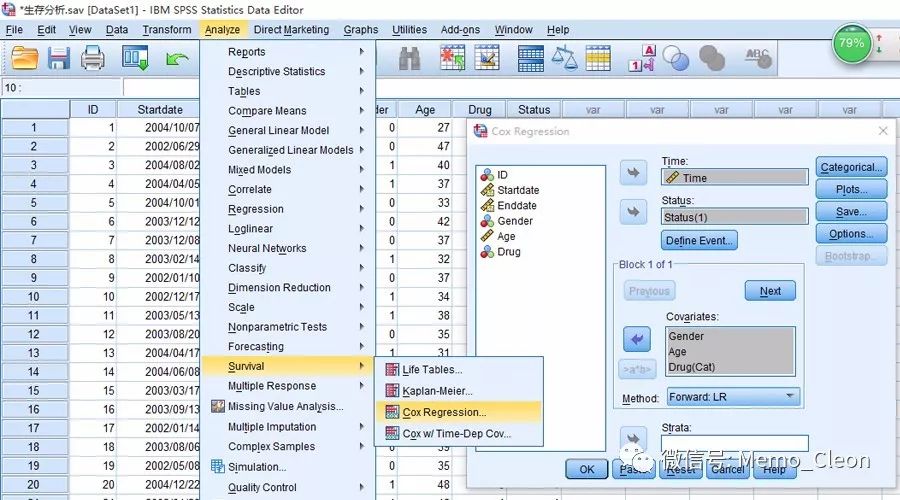
对话框是Kaplan-Meier主对话框和Logistic回归对话框的综合。
- 生存时间(Time):选入生存时间变量,本例为Time
- 状态(Status):生存结局状态变量,是失效事件还是删失数据,本例选入Status。点击定义时间按钮(Define Event…)定义终点事件发生的值,单值(Single Value)处填入表示事件发生的值,本例Status=1时表示HIV患者死亡。
- 协变量(Covariable):本例Gender、Age、Drug
- 变量筛选方法(Method):本例选Forward:LR,各方法的区别可参见因变量二分类资料的logistic回归。
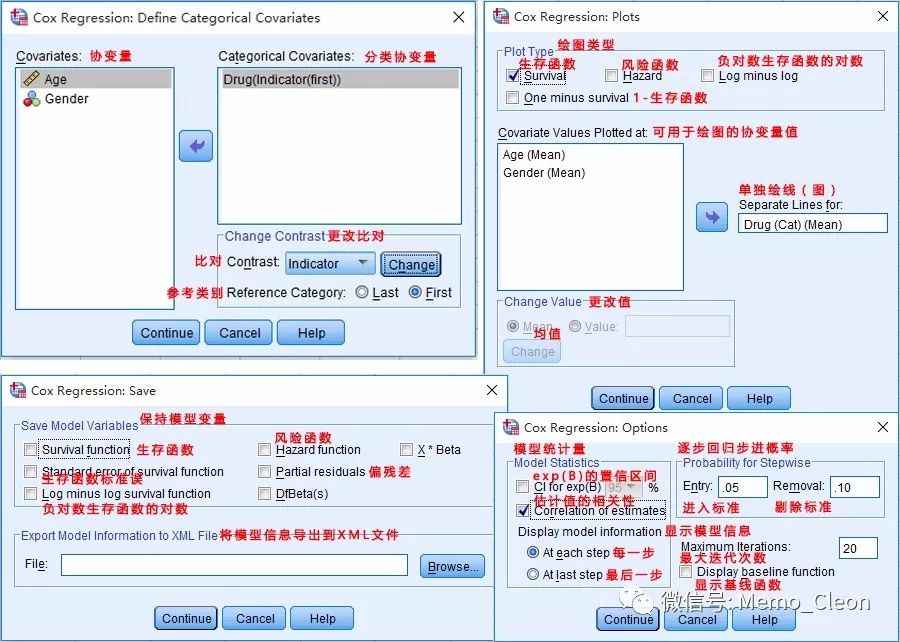
- 分类(Categorical…)、绘图(Plots…)、保存(Save…)、选项(Option…)按钮对应的对话框见下图。特别说一下绘图按钮。需要按某个变量进行分组(或者叫分层)绘制曲线时,可将此变量选入单独绘图(Separate line for…)中,前提是该变量必须通过分类按钮(Categorical…)设置为哑变量(分类变量)方能选入。因此本例将分类变量Drug指定为哑变量,以不用药水平为参照水平,单独绘图文本框选入变量Drug。同时在绘图对话框中选中生存函数,在选项对话框中选中exp(B)的95%CI。
结果及解读
(1)个案处理概要。本例有效分析总例数100例,其中事件数80例,删失数20例。
(2)分类变量编码。本例对Drug进行了分类哑变量设置(按Drug水平进行分组输出绘图,必须进行哑变量设置),结果输出哑变量各分类编码及频数,以不用药为参照水平。

(3)-(7)步结果及解释与因变量二分类logistic回归是类似的。
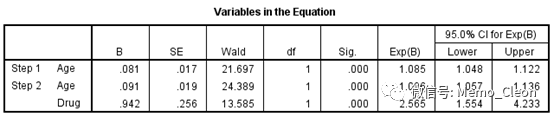
(3)尚未纳入模型方程的变量及其比分检验结果。结果显示如将变量Age和Drug分别纳入方程,方程的改变均有统计学意义;而Gender纳入方程,方程改变无统计学意义。下一步方程首先纳入P值最小的Age。
Block 0: Beginning Block

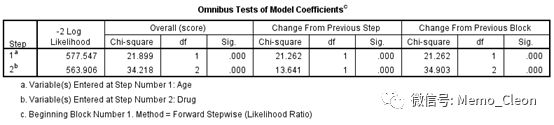
(4)模型系数的综合检验。同logistic回归类似,采用似然比检验。本例共进行了两个变量的引入,-2倍的对数似然值与无效模型(各自变量β均为0)、上一步、上一区块进行比较【注:-2logLR差值服从自由度为引入变量数的卡方分布】结果见下表。由于本例只有一个Block,因此Block与整体model的似然比检验应该是一致的。SPSS在结果输出时,整体比较对应的是比分检验,因此与Block略有差异。本例-2倍的对数似然值逐渐变小,说明引入新的自变量后模型效果更加优秀,比分和似然比检验也显示有统计学意义。
Block 1: Method = Forward Stepwise (Likelihood Ratio)
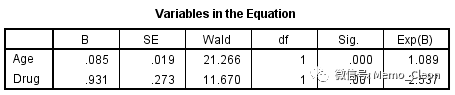
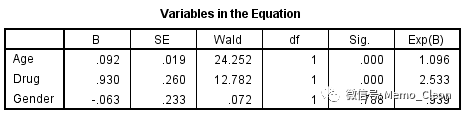
(5)每一步拟合入选方程的变量估计值及Wald检验情况。最终引入变量Age和Drug,表达式h(t)=h0(t)exp(0.091·Age+0.942·Drug)。
Age和Drug的回归系数分别是0.091和0.942,P值均小于0.001,HR值分别为exp(0.091)=1.096、exp(0.042)=2.565。不考虑其他因素的影响,患者的年龄每增加1岁,死亡风险是小1一岁患者的1.096,如要估计相差十岁患者间的死亡风险,则需系数乘以10。不考虑其他因素的影响,患者用药的死亡风险是不用药的死亡风险的2.565倍。
(6)尚未进入模型的自变量是否可能被纳入的比分检验结果,每一步将不在模型中的变量引入模型,模型的改变是否有统计学意义。在Step2时已经没有需要引入的变量了。
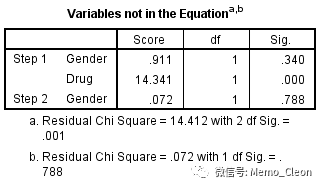
(7)输出每一步被纳入的自变量是否需要被剔除,本例变量剔除方法采用的是Foeward:LR(向前法:似然比检验),默认的剔除标准是0.1。结果显示已纳入的变量一个都不能被剔除
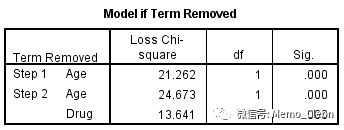
(8)协变量均值和模式值。给出了各变量的平均值及模式值。分类变量的均值实际上是样本构成比,本例将按Drug两水平进行分别绘图。

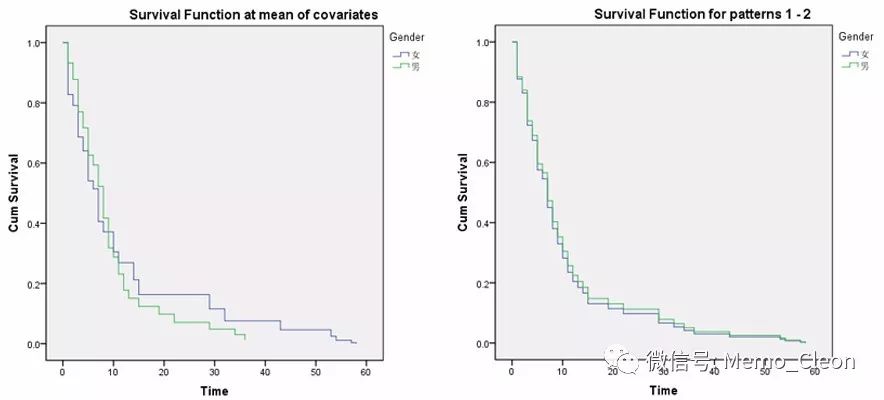
(9)协变量均值处的生存函数:总的生存率变化
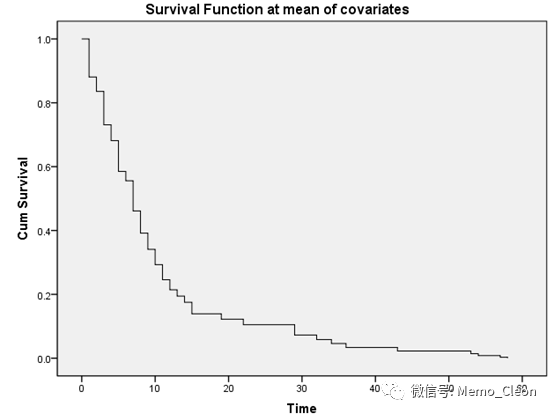
(10)分组累积生存函数曲线。在控制了其他变量后,有无用药组的生存函数曲线比较,图形比较直观的看出,不用药组患者的生存情况优于用药组的患者。
Cox回归要求风险比例假定,实际资料的比例风险假定的检验方法也很多,比如生存概率曲线识别法,残差分析及参数检验等。
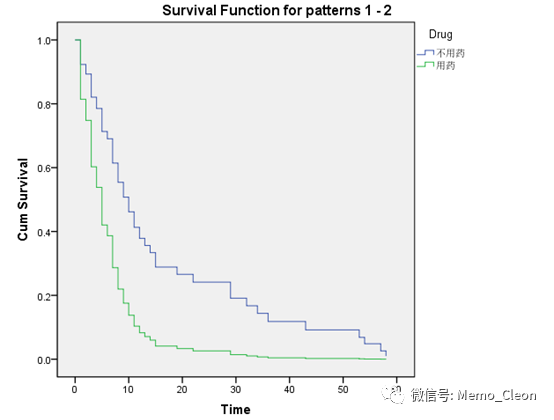
生存概率曲线识别法:以协变量Drug为分组变量生成Kaplan-Meier生存曲线(具体步骤可参见【3】Kaplan-Meier法,在Plot对话框中选中生存函数),结果见下图(左)。如图两组的Kaplan-Meier生存曲线趋势基本一致,无交叉,提示自变量Drug基本满足风险比例假定的要求。该法不能直接对连续型协变量进行分析,如需要分析,需将连续资料转化为分类资料。
负对数生存函数的对数(LML)曲线法:对于满足PH假定两样本的生存资料,可由h(t)=h0(t)exp(βx)推导出ln[-lnS(t)]=ln[-lnS0(t)]+βx,本人数学极差,具体的微积分推导就略过了。以ln[-lnS(t)]对t作图,曲线大致“平行”或者等距,如曲线交叉则违反PH。本例以协变量Drug为分组变量生成负对数生存函数的对数曲线(具体步骤可参见【4】Cox比例风险模型回归,Plot对话框中选中Log minus log),两组对应曲线基本平行,提示基本满足风险比例的假定。
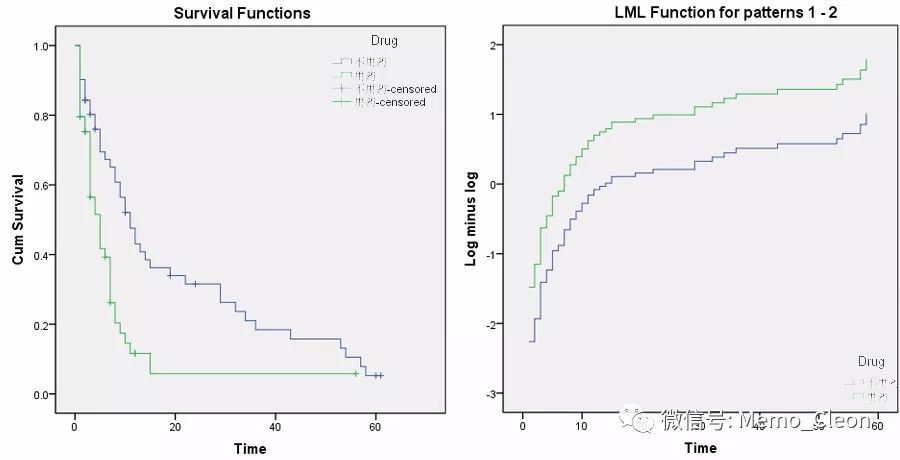
偏残差分析:残差与生存时间不存在线性趋势
①通过Cox Regression过程的保存(Save…)对话框分别获得Gender、Age及Drug的偏残差(Partial residuals);
②分别用残差和生存时间绘制散点图:图表(Graphs)>>图表构建器(Chart Builder):散点图(Scatter/Dot)>>简单散点图(Simple Scatter):横坐标选入生存时间,纵坐标分别选入Gender、Age及Drug的残差。本例Age的散点较为分散,线性趋势不明显,分类资料(Gender、Drug)给出的信息量较差。
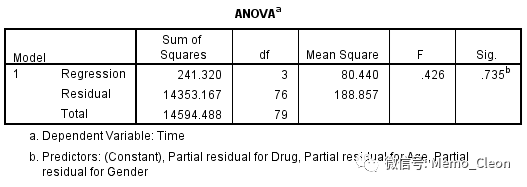
③以生存时间为因变量,Gender、Age和Drug残差,建立线性回归模型。如果模型整体的方差分析无统计学意义(所有自变量的回归系数均为0),则说明所有自变量对生存风险的作用不随时间变化而变化,即满足PH假定;当模型整体的方差分析有统计学意义,则说明至少有一个自变量的系数不为0,需要进一步观察回归系数的检验表格,查看哪些变量的回归系数无统计学意义(无统计学意义表示系数与0没有差异,该自变量对生存风险的作用不随时间变化而变化,满足PH假定)。
分析(Analyze)>>回归(Regression)>>线性(Linear…):因变量(Dependent)选入Time,Independents选入新生成的自变量残差,变量筛选方法Enter。确定。本例三个自变量的系数均无统计学意义,都满足PH假定。
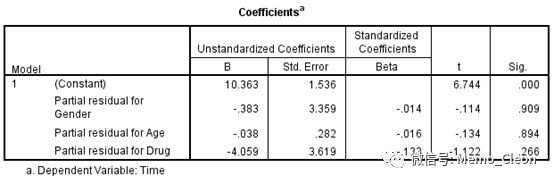
时依协变量检验:构建包含时间的交互作用项并做统计学检验,具体方法可参见本笔记的第五部分:【5】含时依协变量的Cox回归 5.1验证Cox回归模型的比例风险性假设。
当协变量检验显示不满足比例风险假定时,可将不呈比例关系的协变量作为分层变量,然后再将剩余变量进行Cox回归模型分析。如本例,假设Gender不满足PH假定,可在Cox对话框中将Gender选入分层变量框(Strata)中,结果将按男和女两个水平分别输出结果。
该方法分层允许基准风险率在分层变量的各个水平层(本例为男和女)中完全不同,在不同的层中函数曲线可以有不同的形状,但其他协变量的HR在各个时点及层内保持一致。采用这种方法无法分析分层变量对生存的影响强度。
通过哑变量也可以实现分层(Categorical对话框中将需要分层的分类变量设置成哑变量,在Plot对话框中将设置好的分类哑变量选入单独绘线框中),与上述的通过Strata分层不同,基准风险率在不同的性别间成比例变化,函数曲线形状类似,其他因素的HR在各层中保持一致。
层设置与相应结果
Strata:Gender(无论Plot>>Separate Lines for中有无其他分层变量)
Plot>>Separate Lines for:Gender
Strata:Gender(左图)
Plot>>Separate Lines for:Gender(右图)
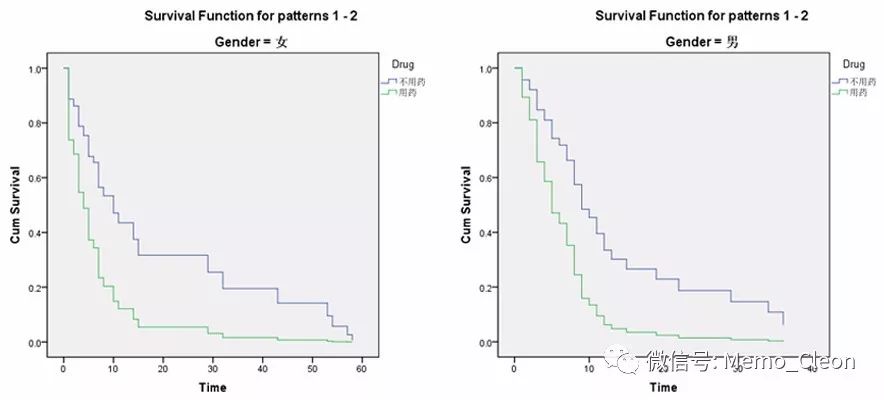
在Strata分层后,也可以哑变量中再次分层绘图。本例如Strata中选入Gender,在单独绘图中选入Drug(首先进行分类变量设置)。
Strata:Gender;
Plot>>Separate Lines for:Gender
则结果在显示上图左图后,紧接着还显示男女两个水平层的Drug分层结果:
不满足PH假定的处理方法还可以采用含时依协变量的Cox分段回归,具体方法可参见本笔记的第五部分:【5】含时依协变量的Cox回归 5.2建立分段Cox回归模型
【5】含时依协变量的Cox回归
可用于验证Cox回归模型的比例风险性假设,建立分段Cox回归模型
5.1 验证Cox回归模型的比例风险性假设
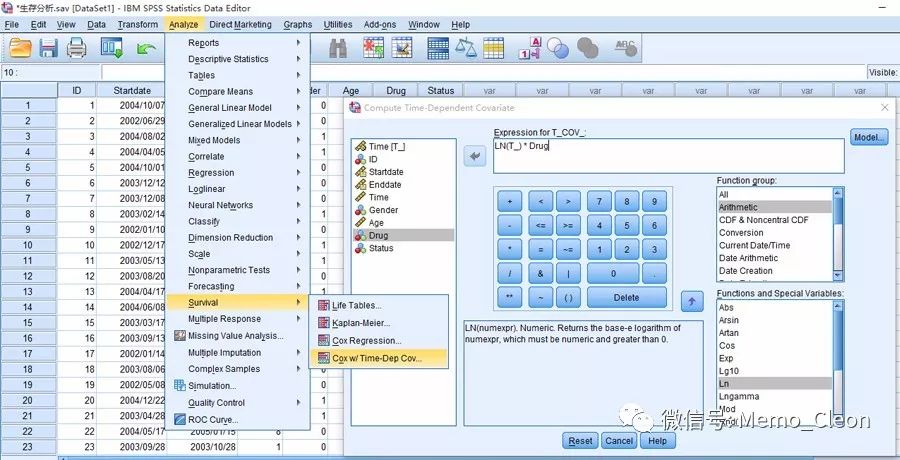
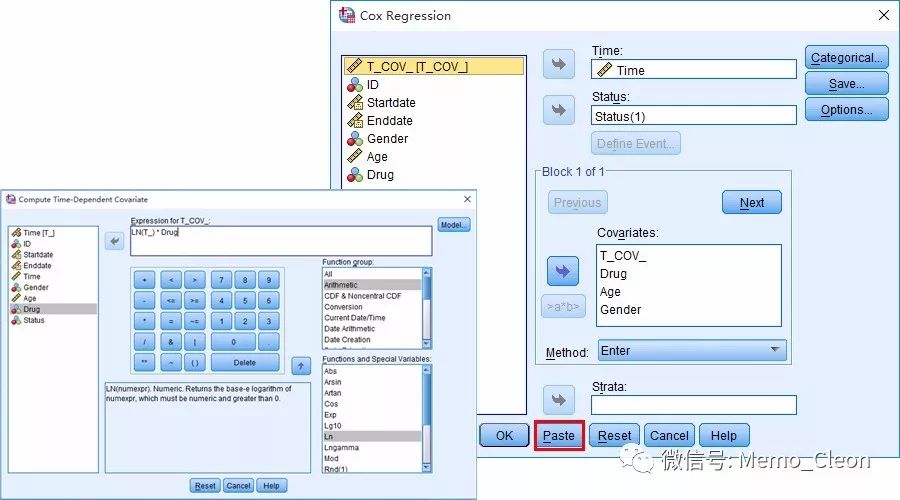
①分析(Analyze)>>生存分析(Survival)>>时依协变量Cox回归(Cox w/Time -Dep Cov……)
Expression for T_COV_: LN(T_)*Drug
变量列表中除了已有的变量外,还有一个变量Time[T_],用此变量代替时间变量(本例为Time)来构建时依协变量,新构建的时依协变量名称为T_COV_。一般时间呈偏态分布,为减少极端值的影响取时间的自然对数。
②点击模型按钮进入Cox回归对话框,操作同风险比例模型的Cox回归一致,具体操作可参见前面的“Cox比例风险模型回归”,不同的是待选变量中多了一个以T_COV_[T_COV_]命名的自变量,也就是我们新构建的自变量Drug的时依协变量。将变量Drug和新构建的T_COV_[T_COV_]选入协变量对话框中,变量筛选方法选择Enter。
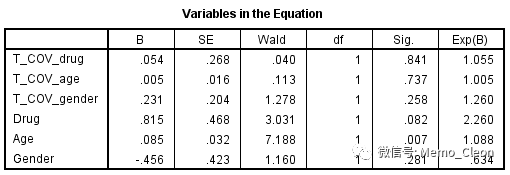
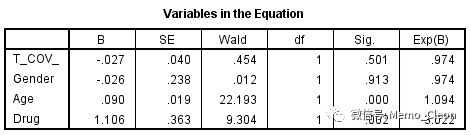
结果如下表,Drug的时依协变量T_COV_的Wald卡方=0.418,P=0.518>0.05,表示Drug的效应不随时间的变化而变化,满足Cox回归的比例风险性假设。

同理,分别构建Gender和Age的时依协变量,检验结果分别为Wald卡方=2.036,P=0.154;Wald卡方=0.054,P=0.816,均满足Cox回归的比例风险性假设。
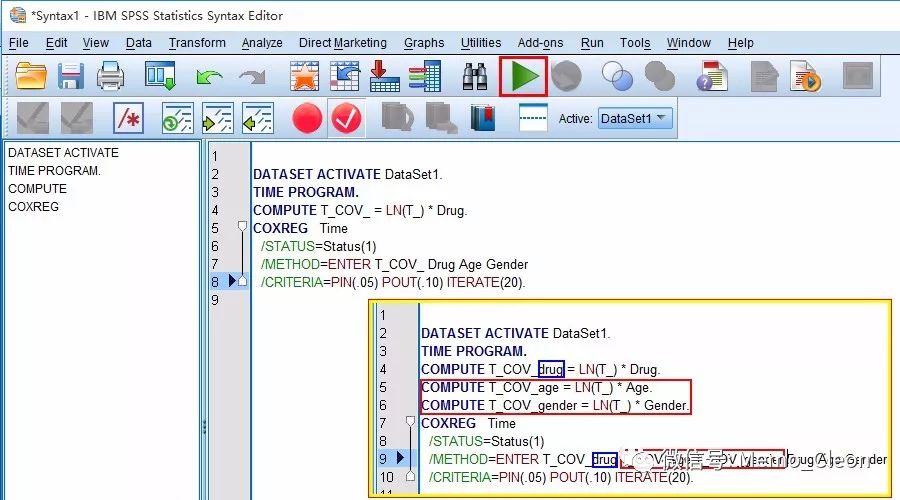
以上相当于单个变量分别进行的分析,但有时可能需要纳入多个时依协变量同时进行分析,而SPSS的Expression for T_COV_一次只能生成一个时依变量。如想同时纳入多个时依变量,需要借助编程功能,方法如下:
构建Drug的时依协变量后进入Cox回归对话框,将变量Drug、Age、Gender以及新构建的时依协变量选入协变量框,变量筛选方法可根据需要进行选择(具体纳入哪些变量可根据专业,或者是经变量筛选后的变量。本例仅为演示,全部纳入)。
点击下方的粘贴按钮(Paste),按下图将原程序修改为黄框内的程序(红框内为修改内容),增加其他时依协变量及其显示,点击运行(工具栏红框内的绿色三角)即可。结果显示在多变量的模型中,几个时依协变量均无统计学意义,均满足Cox回归的比例风险性假设。
5.2 建立分段Cox回归模型
分段模型的思路很简单:比例风险假定虽然在整个研究观察期间内不成立,但在一个较短的时间段内是有效的,所以可以把整个时间轴分为数个时间段,每个时间段分别配合一个风险比例模型。实际操作可以真正将数据分为几个数段分析,也可以建立统一模型,用时间与协变量的交互作用(时依协变量)来实现。
假如本例Drug不符合比例风险假定
- 分析(Analyze)>>生存分析(Survival)>>时依协变量Cox回归(Cox w/Time -Dep Cov……)Expression for T_COV_: T_*Drug
- 点击Model,进入Cox回归对话框Time:选入Time
Status:选入Status;定义事件:单值=1
Covariates:选入T_COV_、Gender、Age、Drug;方法:Enter(本例实际上是满足PH假定的,如果选用其他方法进行变量筛选,则时依协变量不能进入最终的方程。为更好演示操作结果,筛选方法选Enter)
- OK
主要结果如下
本例Drug是符合PH假定的,其效应随着时间的变化保持一致的。本例假设不符合PH假定(T_COV_的P值<0.05),就不能只用HR=Exp(1.106)=3.022来描述Drug的影响强度,Drug的HR应该是一个时间函数,随着时间变化而变化:HR=Exp(1.106-0.027t)。
当个体的状态随时间发生变化,比如患者在治疗期间患者婚姻状况发生了变化,婚姻这个协变量取值变化可能对效应HR造成影响,可构建时依协变量来对模型进行拟合。还有一种情况,如前所言,当PH假定在整个研究观察期间内不成立时,可以把整个时间轴分为数个满足PH假定的时间段,对每个时段进行Cox回归。如本例假定Drug不满足PH假定,中位值在7-8之间结合生存曲线假定分界点为8个月(分界点的确定涉及cut-off值的确认,本次笔记不涉及。此处的8个月也只是假定整个时间段以8个月分为两个时间段后都满足PH)。
按如下表达式建立时依协变量,其余步骤同上
Expression for T_COV_: (T_ >= 8 )* Drug
用逻辑表达式定义的时依协变量,当逻辑表达式为真时取值“1”,为假时取值“0”,“&”表示逻辑与,“|”表示逻辑或。
当生存时间少于8个月,调整Gender和Age后,Drug的回归系数为0.985,HR=exp(0.985)=2.678,用药患者是不用药患者发生死亡风险的2.678倍;
当生存时间大于等于8个月,调整Gender和Age后,Drug的回归系数为0.985-0.189=0.796,HR=exp(0.796)=2.217,用药患者是不用药患者发生死亡风险的2.217倍。
