

HGVS规则下的变异命名专题,不知不觉已经到了最后一期,这一期,分享一下关于蛋白水平的变异命名,本专题的三篇文章看下来,今后的变异命名和变异解读应该可以风雨无阻了。
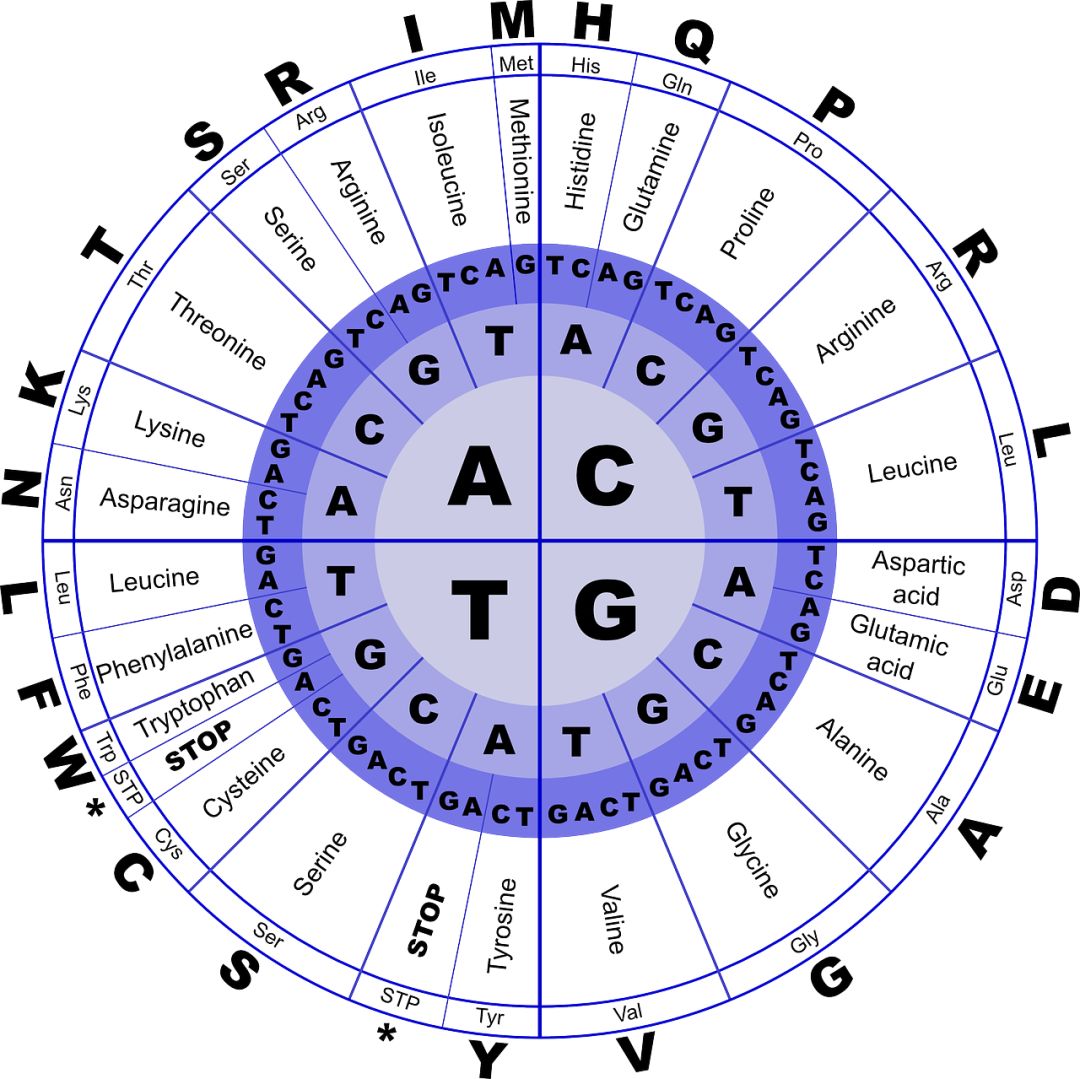
三个碱基组成一个密码子,翻译成一个氨基酸,碱基的变异可导致不同种类的氨基酸的变化,比如:
一个氨基酸变成另一份氨基酸:错义突变(missense)
一个氨基酸变成终止密码子:无义突变(nonsense)
虽然碱基发生变化,但是编码的氨基酸没有变化:同义突变(silent)
注意这里的中英文对应关系哦,尤其是nonsense和silent。
不同的突变类型,都归于上述的氨基酸的变化。
氨基酸也有类似碱基的突变类型:
置换(Substitution)
变异表示形式(Format):
“prefix”“amino_acid”“position”“new_amino_acid”
如p.(Arg54Ser)
“prefix” =参考序列 = p.
“amino_acid” =被替换的氨基酸= Arg
“position” =被替换的氨基酸位置= 54
“new_amino_acid” =新的氨基酸 = Ser
NOTE
1. 这里指的是预测的氨基酸的变化,用圆括号表示,没有经过实验验证,如没有经过RNA或蛋白序列验证的情况。
▼举个栗子▼
错义突变:
LRG_199p1:p.Trp24Cys:24位Trp变为Cys
NP_003997.1:p.(Trp24Cys):24位Trp变为Cys,基于DNA序列推断,无实验证据。
无义突变:
LRG_199p1:p.Trp24Ter(p.Trp24*):24位的Trp密码子变为终止密码子,此处,终止密码子的表示方法一般用两种:“Ter”/“*”。
同义突变:
NP_003997.1:p.Cys188=:虽然碱基发生了改变,但是所处的188位氨基酸没有发生变化。(同义突变用“=”表示)
起始密码子:
LRG_199p1:p.0:不翻译蛋白质
LRG_199p1:p.?(p.Met1?):起始密码子丢失,但无法预测是否有蛋白质翻译
形成新的起始密码子:(一般经过了实验验证)
新起始密码子位于原起始密码子的上游(upstream):
见延伸(Extension)部分
新起始密码子位于原起始密码子的下游(downstream):
NP_003997.1:p.Leu2_Met124del:这里的位置表示的是由于原起始密码子的变化,原氨基酸序列的前123个氨基酸无法翻译,在原序列的124位产生了新的起始密码子。
注意,此处同样遵循最靠近3’法则。
不确定(uncertain)
NP_003997.1:p.(Gly56Ala^Ser^Cys):56位Gly不确定变成了Ala 、Ser、Cys这三种中的哪一种氨基酸。
嵌合现象(mosaic)
LRG_199p1:p.Trp24=/Cys:同DNA水平描述,24位原序列氨基酸Trp和改变后的氨基酸Cys同时存在,但不管两种氨基酸的比例如何,都要把与参考序列相同的氨基酸置于第一位。
缺失(deletion)
变异表示形式(Format):
“prefix”“amino_acid(s)+position(s)_deleted”“del”
如:p.(Cys76_Glu79del)
“prefix” = 参考序列 = p.
“amino_acid(s)+position(s)_deleted”=氨基酸缺失的起始位置 = Cys76_Glu79
“del” = 缺失= del
NOTE
1. 氨基酸的缺失命名规则大部分与DNA水平相似。
3. 碱基缺失应优先考虑蛋白水平变异,最常见的为移码变异。
▼举个栗子▼
LRG_199p1:p.Val7del:7位氨基酸缺失
LRG_199p1:p.(Val7del):预测7位氨基酸缺失,未经过实验验证
p.Gly2_Met46del:参考序列的起始密码子缺失,新的密码子始于参考氨基酸序列的46位
重复(Duplication)
变异表示形式(Format):
“prefix”“amino_acid(s)+position(s)_duplicated”“dup”
比如:p.(Cys76_Glu79dup)
“prefix” =参考序列 = p.
“amino_acid(s)+position(s)_duplicated” = 重复氨基酸范围位置 = Cys76_Glu79
“dup” =重复= dup
NOTE
1. 氨基酸重复一般规则同DNA水平。
▼举个栗子▼
p.Ala3dup:原序列:MetGlyAlaArgSerSerHis,发生该变异后的序列:MetGlyAlaAlaArgSerSerHis
p.(Ala3dup):同上,但是改变以未经过实验验证。
p.Ala3_Ser5dup:第3到5位的氨基酸发生了一次重复。
p.Ser6dup:原序列:MetGlyAlaArgSerSerHis ,变异后的序列:MetGlyAlaArgSerSerSerHis,遵循最靠近3’端原则,位置为第6位,而不是第5位。
移码突变(Frame shift)
变异表示形式(Format):
“prefix”“amino_acid”position”new_amino_acid”“fs”“Ter”“position_termination_site”
如:p.(Arg123LysfsTer34)
“prefix” = 参考序列 = p.
“amino_acid” =发生改变的第一个氨基酸 = Arg
“position” = 氨基酸位置=123
“new_amino_acid” = 突变后新的氨基酸 = Lys
“fs” = 移码=fs
“Ter” = 改变的最后一个氨基酸= Ter / *
“position_termination_site” = 最后一个氨基酸的位置= 34
NOTE
1. 移码突变为一种特殊形式的del/ins,但是在描述的时候,不能列出缺失的那一部分的位置和氨基酸。
▼举个栗子▼
p.Arg97ProfsTer23
第97位的Arg突变为Pro,后续并发生移码,编码23个氨基酸后终止,该形式也可以写成p.Arg97fs。
p.(Tyr4*)
经过序列预测(有括号),第4位的Tyr突变成了终止密码子。可以对照序列帮助理解,原序列: ATGGATGCATACGAGATGAGG.. ,突变后的序列:ATGGATGCATA\_GTCACG (c.12delC) 。
延伸(Extension)
变异表示形式(Format):
N端的延伸(N-terminal) “prefix”“Met1”“ext”“position_new_initiation_site”
如:p.Met1ext-5
“prefix” = 参考序列 = p.
“Met1” = 参考起始密码子= Met1
“ext” = 延伸= ext
“position_new_initiation_site” = 突变后往上游延伸的起始密码子位置= -5
C端的延伸(C-terminal):
“prefix”“Ter_position”“new_amino_acid”“ext”“position_new_termination_site”
如:p.Ter110Glnext*17
“prefix” = 参考序列= p.
“Ter_position” = 参考终止密码子位置= Ter110
“new_amino_acid” = 原终止密码子突变后的编码氨基酸= Gln
“ext” = 延伸=ext
“position_new_termination_site” = 突变后新终止密码子位置= *17
NOTE
延伸也是属于特殊形式的del/ins,或特殊形式的移码突变,在进行变异描述的时候,需要遵循优先权:1)延伸,2)移码突变或del/ins突变。
▼举个栗子▼
p.Met1ext-5
突变后,在5’-UTR区(原起始密码子上游5位)形成了新的起始密码子,该变异也可描述为: p.Met1extMet-5
p.Ter110Glnext*17
注意:该变异也可以描绘为:p.*110Glnext*17,而不能写成:p.Ter110GlnextTer17 ,“Ter17”表示的是17个氨基酸,而不是位置,因此,这里只有用“*”才是正确的。
氨基酸的很多变异类型的命名原则与DNA水平的碱基变异命名原则一致,比如:插入(Insertion)、缺失-插入(Deletion-insertion)、Repeated sequences(重复序列)等。