

近年来,Transformer模型在自然语言处理(NLP)领域中横扫千军,以BERT、GPT为代表的模型屡屡屠榜,目前已经成为了该领域的标准模型。同时,在计算机视觉等领域中,Transformer模型也逐渐得到了重视,越来越多的研究工作开始将这类模型引入到算法中。本文基于2017年Google发表的论文,介绍Transformer模型的原理。
一、为什么要引入Transformer?
最早提出的Transformer模型[1]针对的是自然语言翻译任务。在自然语言翻译任务中,既需要理解每个单词的含义,也需要利用单词的前后顺序关系。常用的自然语言模型是循环神经网络(Recurrent Neural Network,RNN)和卷积神经网络(Convolutional Neural Network,CNN)。
其中,循环神经网络模型每次读入一个单词,并基于节点当前的隐含状态和输入的单词,更新节点的隐含状态。从上述过程来看,循环神经网络在处理一个句子的时候,只能一个单词一个单词按顺序处理,必须要处理完前边的单词才能开始处理后边的单词,因此循环神经网络的计算都是串行化的,模型训练、模型推理的时间都会比较长。
另一方面,卷积神经网络把整个句子看成一个1*D维的向量(其中D是每个单词的特征的维度),通过一维的卷积对句子进行处理。在卷积神经网络中,通过堆叠卷积层,逐渐增加每一层卷积层的感受野大小,从而实现对上下文的利用。由于卷积神经网络对句子中的每一块并不加以区分,可以并行处理句子中的每一块,因此在计算时,可以很方便地将每一层的计算过程并行化,计算效率高于循环神经网络。但是卷积神经网络模型中,为了建立两个单词之间的关联,所需的网络深度与单词在句子中的距离正相关,因此通过卷积神经网络模型学习句子中长距离的关联关系的难度很大。
Transformer模型的提出就是为了解决上述两个问题:(1)可以高效计算;(2)可以准确学习到句子中长距离的关联关系。
二、Transformer模型介绍
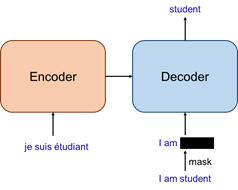
如下图所示,Transformer模型采用经典的encoder-decoder结构。其中,待翻译的句子作为encoder的输入,经过encoder编码后,再输入到decoder中;decoder除了接收encoder的输出外,还需要当前step之前已经得到的输出单词;整个模型的最终输出是翻译的句子中下一个单词的概率。
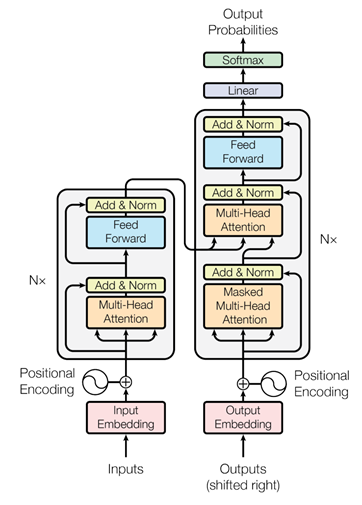
现有方法中,encoder和decoder通常都是通过多层循环神经网络或卷积实现,而Transformer中则提出了一种新的、完全基于注意力的网络layer,用来替代现有的模块,如下图所示。图中encoder、decoder的结构类似,都是由一种模块堆叠N次构成的,但是encoder和decoder中使用的模块有一定的区别。具体来说,encoder中的基本模块包含多头注意力操作(Multi-Head Attention)、多层感知机(Feed Forward)两部分;decoder中的基本模块包含2个不同的多头注意力操作(Masked Multi-Head Attention和Multi-Head Attention)、多层感知机(Feed Forward)三部分。
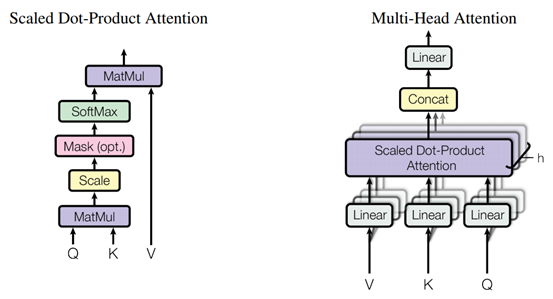
在上述这些操作中,最核心的部分是三种不同的Multi-Head Attention操作,该操作的过程如下图所示,可以简单理解为对输入feature的一种变换,通过特征之间的关系(attention),增强或减弱特征中不同维度的强度。模型中使用的三种注意力模块如下:
- Encoder中的Multi-Head Attention:encoder中的multi-head attention的输入只包含编码器中上一个基本模块的输出,使用上一个基本模块的输出计算注意力,并调整上一个基本模块的输出,因此是一种“自注意力”机制;
- Decoder中的Masked Multi-Head Attention:Transformer中,decoder的输入是完整的目标句子,为了避免模型利用还没有处理到的单词,因此在decoder的基础模块中,在“自注意力”机制中加入了mask,从而屏蔽掉不应该被模型利用的信息;
- Decoder中的Multi-Head Attention:decoder中,除了自注意力外,还要利用encoder的输出信息才能正确进行文本翻译,因此decoder中相比encoder多使用了一个multi-head attention来融合输入语句和已经翻译出来的句子的信息。这个multi-head attention结合使用decoder中前一层“自注意力”的输出和encoder的输出计算注意力,然后对encoder的输出进行变换,以变换后的encoder输出作为输出结果,相当于根据当前的翻译结果和原始的句子来确定后续应该关注的单词。
除核心的Multi-Head Attention操作外,作者还采用了位置编码、残差连接、层归一化、dropout等操作将输入、注意力、多层感知机连接起来,从而构成了完整的Transformer模型。通过修改encoder和decoder中堆叠的基本模块数量、多层感知机节点数、Multi-Head Attention中的head数量等参数,即可得到BERT、GPT-3等不同的模型结构。
三、实验效果
实验中,作者在newstest2013和newstest2014上训练模型,并测试了模型在英语-德语、英语-法语之间的翻译精度。实验结果显示,Transformer模型达到了State-of-the-art精度,并且在训练开销上比已有方法低一到两个数量级,展现出了该方法的优越性。
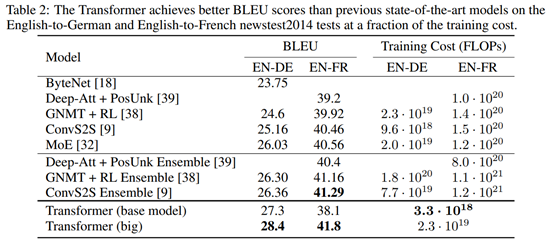
与已有方法的对比实验,显示出更高的BLEU得分和更低的计算开销:
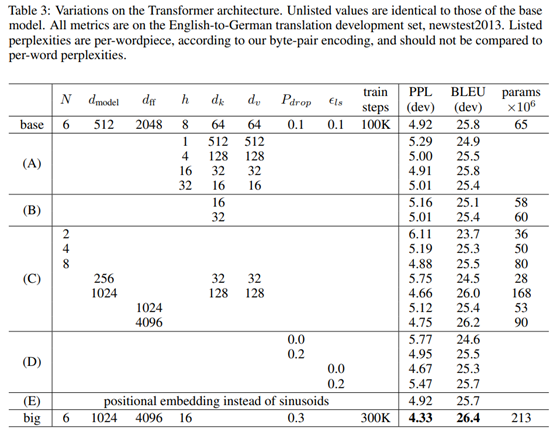
模块有效性验证,模型中每个单次的特征维度、多头注意力中头的数量、基本模块堆叠数量等参数对模型的精度有明显的影响:
参考文献
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin. Attention Is All You Need. NIPS 2017.