

大多数时候,临床研究是一个探索因果关系的过程,例如疾病的病因、诊疗干预的有效性和安全性研究等。混杂作为临床研究设计与统计分析中的“熟面孔”,大家对其基本概念一定不陌生,其本质是一种因果效应的混淆。因此,我们在研究过程中需要去识别潜在的混杂因素以及选择合适的控制方法。今天,小编向大家介绍两个有关混杂的概念——未测量混杂与残余混杂。
未测量混杂指的是在研究过程中未识别调整的混杂,往往是因为缺少时间、金钱或者缺乏有关混杂因素的认识等因素导致的。根据有向无环图的“后门原则”,如果我们控制了已知的混杂因素(常用的控制方法有匹配、分层和回归分析等),暴露与结局间仍然存在由未测量混杂构建的通路,所以我们无法获得真实的因果效应。
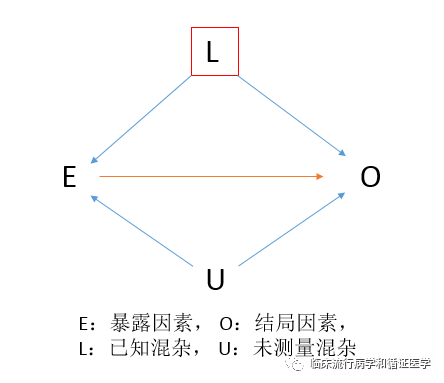
此时,可能有人会问:“假设我们能识别所有的潜在混杂因素,是不是就能获得准确的因果效应呢?”答案是仍然不一定的,因为可能存在残余混杂。
残余混杂指的是虽然已经被识别调整的混杂因素,但未被调整完全,主要是因为测量不准确和误差导致的。例如,在医学研究中,社会地位因素是一个经常被识别的混杂因素,但是用哪种变量来替代社会地位的高低却很困难。如果研究者单单根据受试者的每月工资或者年薪来进行社会地位分层就可能引起残余混杂,因为收入高低不能完全等价于社会地位高低。再举个例子,一项临床研究中,我们已经识别受试者体重是一个潜在的混杂因素,用电子称可以准确的测量每个人的体重,而如果观察者通过目测来衡量每个人的重量将会存在误差,依据目测数据进行混杂控制将会引起残余混杂。因此,混杂虽然是大家的“熟面孔”,但是“她”的心犹如海底针,很难被人理解。
随着临床研究的发展,学者们对于混杂的判别标准以及控制策略逐渐有了新的认识。例如,有向无环图可以直观清晰的理解变量间的因果关联,负控制可以识别是否存在未测量混杂,倾向评分法和工具变量法可以在复杂的研究背景下去探索因果关系。感兴趣的读者可以寻找相关文献进行自我学习,当然也可以在留言处与小编讨论。