在SPSS软件中,Data View(数据视图)在默认情况下每一行就是一条记录,通常情况下我们也是这样录入数据的。但是,在有些情况下我们得到的数据可能是已经初步汇总过的,如下面所说的情况,如果有168个相同的观察数据,每一行就是一个记录,则需要输入168行,这样做非常麻烦。SPSS当然考虑了这个问题,并且比较容易地解决了这个问题。具体办法是使用频数格式录入数据,即相同取值的观测只录入一次,另加一个频数变量记录该数值共出现了多少次。这样就需要在分析前先用Data(数据)主菜单中的Weight Cases(加权个案)过程将数据指定为该种格式。然后再进行分析。数据加权的方法如下:
加权个案案例:为了研究抽烟与肺癌的关系,随机采访了45个正常人与55个肺癌患者,询问记录了他们是否抽烟,数据记录结果详见下表:
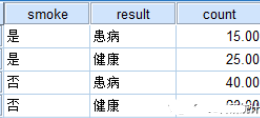
对数据进行加权操作的方法如下:
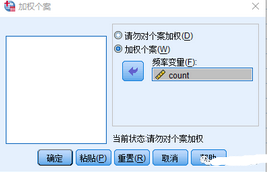
依次点击菜单“数据——加权个案”,其界面如下图所示。点击选中“加权个案”单选框,将左侧变量列表中“人数”变量选中进入“频率变量”选框作为加权变量。点击确认。
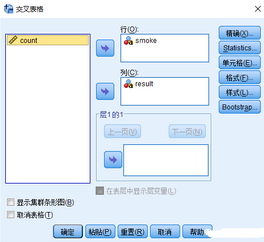
加权后的数据表面上看没什么变化,但在旗分析过程中会产生差异。以下以列联表交叉表分析为例,解释加权变量的应用。
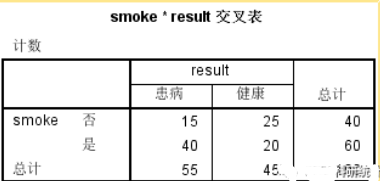
在数据没有加权后得出的交叉表如下表,可以看出SPSS只按照实际的行数进行了统计,不能真实的反应实际情况。
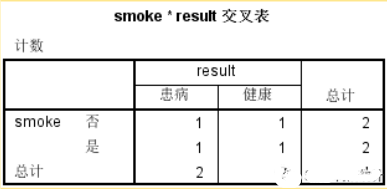
而加权之后所得出的交叉表清晰的反映出了是否吸烟所对应的患病与健康的人数,可以清晰的发现吸烟的患者要明显高于未吸烟的患者。