

FPKM, 是expected number of fragments per kilobase of transcript sequence per millions base pairs sequenced缩写。直译过来就是每百万测序碱基中每千个转录子测序碱基中所包含的测序片断数。与RPKM不同的是,RPKM是直接使用的reads数,而对于FPKM,如果是pair-end的话有可能有些mapped至基因组的是一对,那就算一个片断,如果map至基因组的是只有一侧的read,也算一个片断。
FPKM的公式就可以从字面上写成:
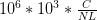
其中C是map至该基因的外显子上的片断数,N是所有map至基因组的测序reads的碱基数,L就是该基因外显子碱基全长。
在其文献(Transcript assembly and quantification by RNA-Seq reveals unannotated transcripts and isoform switching during cell differentiation)Supplementary Text and Figures中是这样描述的:
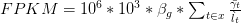
其中beta和gamma都是likelihood function中的参数。lt被定义为
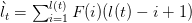
因为,假设transcript t的长度为l(t),那么随机分布时在某一位置t出现长度为k的片段的概率为:
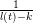
在cuffdiff中,它会将同一组中所有的样品试为同一来源样品处理,这就是为什么同一组内如果有三个样品的话,最终得到FPKM值并不是三个样品单独运算得到的FPKM值的平均值。
来自外部的引用