

作者:陈亮 单位:中科院微生物所, 编辑: 刘永鑫
编者按:上个月菌群月坛,在军科院听取王军组陈亮博士分享网络分析的经验,不仅使我对网络的背景知识有了更全面的认识,更使我手上一个关于菌根的课题有极大的启示。这么好的知识,当然希望和大家分享,故约稿陈博士在“宏基因组”发布一下他的经验,感谢陈博士的整理和分享。下面是正文:
网络分析背景知识
近年来,随着计算机技术的发展,网络科学研究在社会网络方面的分析方法已经成熟,从而促进了网络分析方法向其他领域的渗透,例如:信号传导网络、神经网络、代谢通路网络、基因调控网络、生态网络等。
基于图论(Graph theory)的网络科学认为,任何非连续事物之间的关系都可以用网络来表示,通过将互联网内的电脑、社会关系中的个人、生物的基因等不同属性的实体抽象为节点(Node),并用连接(Link)来展示实体之间的关系,通过量化以节点和连接为组件的网络结构指数(Index),从而能够在统一的框架下寻找复杂系统的共性。
目前生态学领域大家用到的网络图多为基于群落数据相关性构建的Co-occurrence网络图。此类网络可以采用R中igraph包构建并实现出图。当然,除此之外,还有一些非命令行的软件,例如cytoscape,gephi,pajek等。但我认为,对于R使用者来说,通过R做图还是最方便的。大致的流程如下图所示:

1)根据观察,实验或者相关性推断来确定物种间的联系。Co-occurrence网络的构建多是基于相关性推断来构建的。常用的相关性推断方法有Pearson,Spearman, Sparcc等方法。
2)通过构建的相关性矩阵或者相互作用列表来构建igraph对象。常用的方法有以下三种,分别由graph_from_incidence_matrix,graph_from_adjacency_matrix,graph_from_edgelist三个函数获得,详细信息参照igraph官方帮助文档。第一种数据格式是普通矩阵,矩阵中数字代表行列所代表的物种间存在联系,这种联系可通过实验或观察来得到。第二种数据格式是邻接矩阵,物种间相关性计算得到的通常为此种形式。第三种为边列表(edgelist),共两列数据,分别代表网络内的节点名称,每一行代表这两个节点间存在着联系。

3)计算网络的各种参数,用以推断网络的性质。
常用网络参数有:
平均路径长度(Average path length):网络中任意两个节点之间的距离的平均值。其反映网络中各个节点间的分离程度。现实网络通常具有“小世界(Small-world)”特性。
聚集系数(Clustering coefficient):分局域聚类系数和全局聚集系数,是反映网络中节点的紧密关系的参数,也称为传递性。整个网络的全局聚集系数C表征了整个网络的平均的“成簇性质”。
介数(Betweenness):网络中不相邻的节点i和j之间的通讯主要依赖于连接节点i和j的最短路径。如果一个节点被许多最短路径经过,则表明该节点在网络中很重要。 经过节点n的数量所占比例,介数反映了某节点在通过网络进行信息传输中的重要性。
连接性 (Connectance): 网络中物种之间实际发生的相互作用数之和(连接数之和)占总的潜在相互作用数(连接数)的比例,可以反映网络的复杂程度。
此外还包括:度分布(Degree distribution)、平均度(Average degree)、平均介数(Average betweenness)、平均最近邻度(Average nearest-neighbor degree)、直径(Diameter)、介数中心性(Betweenness centralization)和度中心性(Degree centralization)等参数。 各网络参数计算方法及意义参见igraph.org官方帮助文档。
群落数据co-occurrence实例
网络分析需要两个文件,OTU表和OTU的属性;具体格式见测试数据下载链接:https://pan.baidu.com/s/1qYQIRaG 密码:qfes
1.最简单的网络图
# 设置工作目录:请修改下方目录或在Rstudio的Session菜单中选择下载测试数据所在的目录
# setwd("~/Downloads/chenliang")
# 安装需要的包,默认不安装,没安装过的请取消如下注释
# install.packages("igraph")
# install.packages("psych")
# 加载包
library(igraph)
library(psych)
# 读取otu-sample矩阵,行为sample,列为otu
otu = read.table("otu_table.txt",head=T,row.names=1)
# 计算OTU间两两相关系数矩阵
# 数据量小时可以用psych包corr.test求相关性矩阵,数据量大时,可应用WGCNA中corAndPvalue, 但p值需要借助其他函数矫正
occor = corr.test(otu,use="pairwise",method="spearman",adjust="fdr",alpha=.05)
occor.r = occor$r # 取相关性矩阵R值
occor.p = occor$p # 取相关性矩阵p值
# 确定物种间存在相互作用关系的阈值,将相关性R矩阵内不符合的数据转换为0
occor.r[occor.p>0.05|abs(occor.r)<0.6] = 0
# 构建igraph对象
igraph = graph_from_adjacency_matrix(occor.r,mode="undirected",weighted=TRUE,diag=FALSE)
igraph
# NOTE:可以设置weighted=NULL,但是此时要注意此函数只能识别相互作用矩阵内正整数,所以应用前请确保矩阵正确。
# 可以按下面命令转换数据
# occor.r[occor.r!=0] = 1
# igraph = graph_from_adjacency_matrix(occor.r,mode="undirected",weighted=NULL,diag=FALSE)
# 是否去掉孤立顶点,根据自己实验而定
# remove isolated nodes,即去掉和所有otu均无相关性的otu 可省略,前期矩阵已处理过
bad.vs = V(igraph)[degree(igraph) == 0]
igraph = delete.vertices(igraph, bad.vs)
igraph
# 将igraph weight属性赋值到igraph.weight
igraph.weight = E(igraph)$weight
# 做图前去掉igraph的weight权重,因为做图时某些layout会受到其影响
E(igraph)$weight = NA
# 简单出图
# 设定随机种子数,后续出图都从同一随机种子数出发,保证前后出图形状相对应
set.seed(123)
plot(igraph,main="Co-occurrence network",vertex.frame.color=NA,vertex.label=NA,edge.width=1,
vertex.size=5,edge.lty=1,edge.curved=TRUE,margin=c(0,0,0,0))
最简单的点线网络图
2.按相关类型设置边颜色
# 如果构建网络时,weighted=NULL,此步骤不能统计 sum(igraph.weight>0)# number of postive correlation sum(igraph.weight<0)# number of negative correlation # set edge color,postive correlation 设定为red, negative correlation设定为blue E.color = igraph.weight E.color = ifelse(E.color>0, "red",ifelse(E.color<0, "blue","grey")) E(igraph)$color = as.character(E.color) # 改变edge颜色后出图 set.seed(123) plot(igraph,main="Co-occurrence network",vertex.frame.color=NA,vertex.label=NA,edge.width=1, vertex.size=5,edge.lty=1,edge.curved=TRUE,margin=c(0,0,0,0))

边按相关性着色,正相关为红色,负相关为蓝色
3.按相关性设置边宽度
# 可以设定edge的宽 度set edge width,例如将相关系数与edge width关联 E(igraph)$width = abs(igraph.weight)*4 # 改变edge宽度后出图 set.seed(123) plot(igraph,main="Co-occurrence network",vertex.frame.color=NA,vertex.label=NA, vertex.size=5,edge.lty=1,edge.curved=TRUE,margin=c(0,0,0,0))
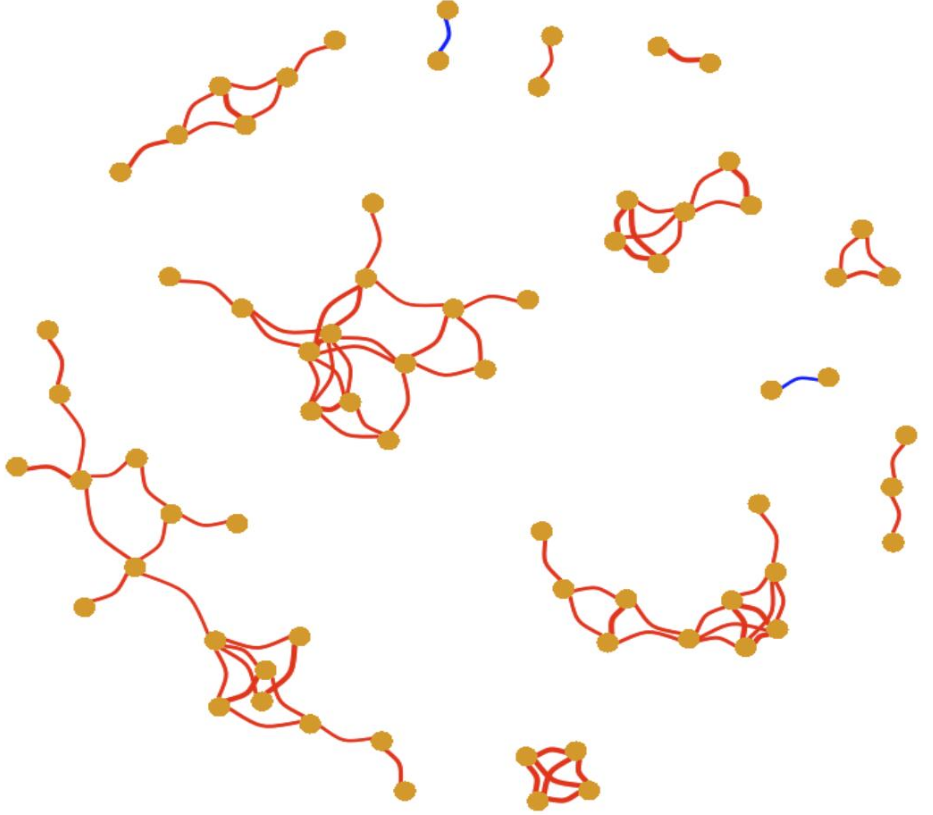
边宽度为4倍相关系数绝对值,看看边是不是有粗有细,越粗代表相关绝对值越大
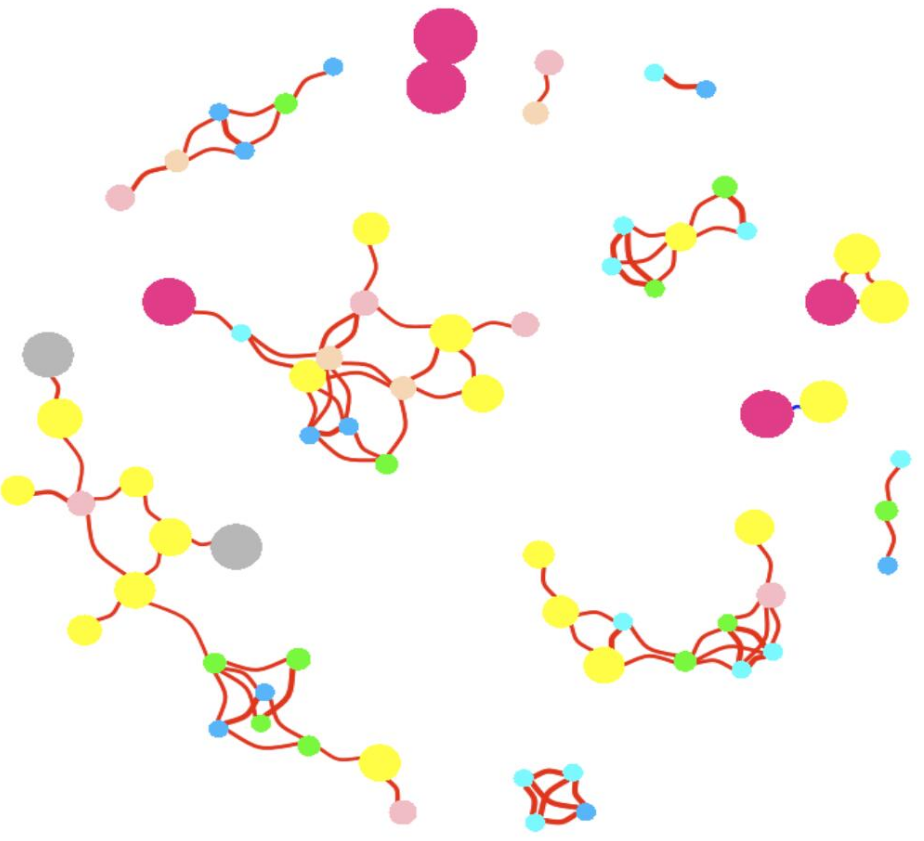
4.设置点的颜色和大小属性对应物种和丰度
# 添加OTU注释信息,如分类单元和丰度
# 另外可以设置vertices size, vertices color来表征更多维度的数据
# 注意otu_pro.txt文件为我随机产生的数据,因此网络图可能不会产生特定的模式或规律。
otu_pro = read.table("otu_pro.txt",head=T,row.names=1)
# set vertices size
igraph.size = otu_pro[V(igraph)$name,] # 筛选对应OTU属性
igraph.size1 = log((igraph.size$abundance)*100) # 原始数据是什么,为什么*100再取e对数
V(igraph)$size = igraph.size1
# set vertices color
igraph.col = otu_pro[V(igraph)$name,]
levels(igraph.col$phylum)
levels(igraph.col$phylum) = c("green","deeppink","deepskyblue","yellow","brown","pink","gray","cyan","peachpuff") # 直接修改levles可以连值全部对应替换
V(igraph)$color = as.character(igraph.col$phylum)
set.seed(123)
plot(igraph,main="Co-occurrence network",vertex.frame.color=NA,vertex.label=NA,
edge.lty=1,edge.curved=TRUE,margin=c(0,0,0,0)) 点大小对应OTU丰度,颜色对应门分类学种类
点大小对应OTU丰度,颜色对应门分类学种类
5.调整布局样式
# 改变layout,layout有很多,具体查看igraph官方帮助文档。 set.seed(123) plot(igraph,main="Co-occurrence network",layout=layout_with_kk,vertex.frame.color=NA,vertex.label=NA, edge.lty=1,edge.curved=TRUE,margin=c(0,0,0,0)) set.seed(123) plot(igraph,main="Co-occurrence network",layout=layout.fruchterman.reingold,vertex.frame.color=NA,vertex.label=NA, edge.lty=1,edge.curved=TRUE,margin=c(0,0,0,0))
不同的布局选项,和上图有什么变化
6.按模块着色
# 模块性 modularity fc = cluster_fast_greedy(igraph,weights =NULL)# cluster_walktrap cluster_edge_betweenness, cluster_fast_greedy, cluster_spinglass modularity = modularity(igraph,membership(fc)) # 按照模块为节点配色 comps = membership(fc) colbar = rainbow(max(comps)) V(igraph)$color = colbar[comps] set.seed(123) plot(igraph,main="Co-occurrence network",vertex.frame.color=NA,vertex.label=NA, edge.lty=1,edge.curved=TRUE,margin=c(0,0,0,0))
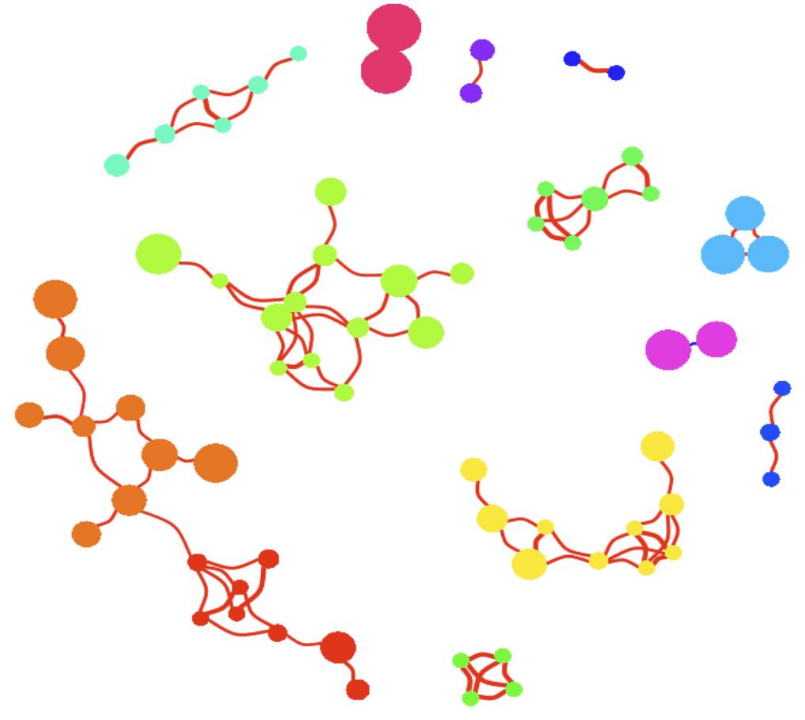
按划分的模块着色,结果中也很常用
7.显示标签和点轮廓
# 最后添加删除color和label项可显示标签和点颜色边框 plot(igraph,main="Co-occurrence network",vertex.frame.color=NA,vertex.label=NA, edge.lty=1,edge.curved=TRUE,margin=c(0,0,0,0))
 最后的效果
最后的效果
8.常用网络属性
# network property # 边数量 The size of the graph (number of edges) num.edges = length(E(igraph)) # length(curve_multiple(igraph)) num.edges # 顶点数量 Order (number of vertices) of a graph num.vertices = length(V(igraph))# length(diversity(igraph, weights = NULL, vids = V(igraph))) num.vertices # 连接数(connectance) 网络中物种之间实际发生的相互作用数之和(连接数之和)占总的潜在相互作用数(连接数)的比例,可以反映网络的复杂程度 connectance = edge_density(igraph,loops=FALSE)# 同 graph.density;loops如果为TRUE,允许自身环(self loops即A--A或B--B)的存在 connectance # 平均度(Average degree) average.degree = mean(igraph::degree(igraph))# 或者为2M/N,其中M 和N 分别表示网络的边数和节点数。 average.degree # 平均路径长度(Average path length) average.path.length = average.path.length(igraph) # 同mean_distance(igraph) # mean_distance calculates the average path length in a graph average.path.length # 直径(Diameter) diameter = diameter(igraph, directed = FALSE, unconnected = TRUE, weights = NULL) diameter # 群连通度 edge connectivity / group adhesion edge.connectivity = edge_connectivity(igraph) edge.connectivity # 聚集系数(Clustering coefficient):分局域聚类系数和全局聚集系数,是反映网络中节点的紧密关系的参数,也称为传递性。整个网络的全局聚集系数C表征了整个网络的平均的“成簇性质”。 clustering.coefficient = transitivity(igraph) clustering.coefficient no.clusters = no.clusters(igraph) no.clusters # 介数中心性(Betweenness centralization) centralization.betweenness = centralization.betweenness(igraph)$centralization centralization.betweenness # 度中心性(Degree centralization) centralization.degree = centralization.degree(igraph)$centralization centralization.degree
通过以上的学习,大家是不是可以一步步基于OTU表和注释,用R实现高大上的网络分析和绘制了呢?想要提高,还得多读,多练,多思考,解决科学问题是关键!