

Illumina 测序原理
在进入本期的正题之前,我们需要了解一下 Illumina 的测序原理,在这里用一张图简单的展示一下:

图1 Illumina 测序原理
(图片来自https://www.illumina.com/documents/products/techspotlights/techspotlight_sequencing.pdf)
重测序建库过程可以简单的概括为:
- 随机打断、加A、加接头 (图1A)
- 桥式 PCR 扩增成簇 (图1B - F)
- 进行测序反应 (图1G - H)
我们的测序结果中为什么含有接头序列呢?
从图1 A 中我们看到,在建库时把 DNA 随机打断为特定长度的片段,然后在每个片段的两端都连上了接头,新形成的测序片段可用图2简单表示:
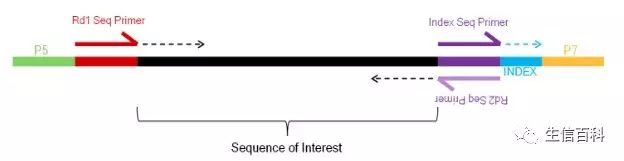
图2 测序片段构成示例 (图片来自http://nextgen.mgh.harvard.edu/CustomPrimer.html)
图中显示的是仅单端有 Index 的情况,如果 polling 的样品较多时,则双端均会有 Index;
如果建库时未用标准的试剂盒、barcode 位于插入片段开始或者结尾的话 (比如某些 GBS 文库),双端可能均没有 Index。
只有当插入片段的长度小于测序的读长 (PE125 中的 125 就是测序反应的读长) 时才会在测序结果中出现接头序列。我们用一张图简单地介绍一下:
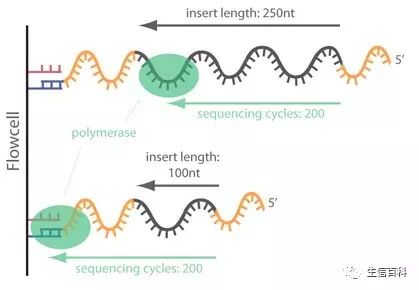
图3 测序结果中出现序列的原因
(图片来自https://www.ecseq.com/support/ngs/trimming-adapter-sequences-is-it-necessary)
图3 上半部分显示插入片段长度大于测序读长的情况,这时我们得到的都是未含有测序接头的正常 reads;
图3 下半部分显示插入片段长度小于测序读长的情况,这时我们得到的是含有测序接头的 reads;
如果插入片段长度为124,测序读长为125,那么测序得到的 read 里会有 1 碱基的接头序列;
一般的建库流程 (如重测序、外显子测序、简化基因组测序等) 会有片段选择步骤,只要控制好片段区间,测序结果中一般不会出现测序接头或者接头含量很少;
某些特殊的文库 (如小 RNA 文库) 插入片段很短,测序得到的每条 reads 都会有部分接头序列出现。
Reads 中的接头我们该如何处理呢?
关于是否有必要去掉 reads 中的接头序列存在争议。测序接头是人工合成的、不会出现在目标基因组中的序列,它的存在会降低 mappping quality,增加不能 map 的序列,个人觉得我们应该在质控阶段截掉接头序列 (推荐做法) 或者去除含有接头序列的 reads。