

Traditional Pooling Methods
要想真正的理解Global Average Pooling,首先要了解深度网络中常见的pooling方式,以及全连接层。
众所周知CNN网络中常见结构是:卷积、池化和激活。卷积层是CNN网络的核心,激活函数帮助网络获得非线性特征,而池化的作用则体现在降采样:保留显著特征、降低特征维度,增大kernel的感受野。深度网络越往后面越能捕捉到物体的语义信息,这种语义信息是建立在较大的感受野基础上。已古人的例子来做解释,想必大家都知道盲人摸象这个成语的来历,每个盲人只能触摸到大象的一部分,也就是只能获得local response,基于这些local response,盲人们很难猜对他们到底在摸什么。即使是一个明眼人,眼睛紧贴这大象后背看,也很难猜到看的是什么。这个例子告诉我们局部信息很难提供更高层的语义信息,因此对feature map降维,进而增大后面各层kernel的感受野是一件很重要的事情。另外一点值得注意:pooling也可以提供一些旋转不变性。
Fully Connected layer
很长一段时间以来,全连接网络一直是CNN分类网络的标配结构。一般在全连接后会有激活函数来做分类,假设这个激活函数是一个多分类softmax,那么全连接网络的作用就是将最后一层卷积得到的feature map stretch成向量,对这个向量做乘法,最终降低其维度,然后输入到softmax层中得到对应的每个类别的得分。
全连接层如此的重要,以至于全连接层过多的参数重要到会造成过拟合,所以也会有一些方法专门用来解决过拟合,比如dropout。
在NIN(Network in Network) 这篇论文中提出了全局平均池化的概念,究竟他和之前的全连接层有什么区别呢?
全连接存在的问题:参数量过大,降低了训练的速度,且很容易过拟合
全连接层将卷积层展开成向量之后不还是要针对每个feature map进行分类,而GAP的思路就是将上述两个过程合二为一,一起做了。如图所示:
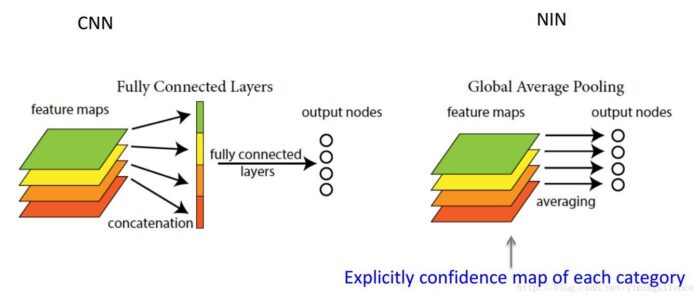
由此就可以比较直观地说明了。这两者合二为一的过程我们可以探索到GAP的真正意义是:对整个网路在结构上做正则化防止过拟合。其直接剔除了全连接层中黑箱的特征,直接赋予了每个channel实际的内别意义。
实践证明其效果还是比较可观的,同时GAP可以实现任意图像大小的输入。但是值得我们注意的是,使用gap可能会造成收敛速度减慢。
参见 《关于global average pooling理解和介绍》
global average pooling 与 average pooling 的差别就在 "global" 这一个字眼上。global 与 local 在字面上都是用来形容 pooling 窗口区域的。 local 是取 feature map 的一个子区域求平均值,然后滑动这个子区域; global 显然就是对整个 feature map 求平均值了。