

1. 神经网络的超参数分类
神经网路中的超参数主要包括:
1. 学习率 η
2. 正则化参数 λ
3. 神经网络的层数 L
4. 每一个隐层中神经元的个数 j
5. 学习的回合数Epoch
6. 小批量数据 minibatch 的大小
7. 输出神经元的编码方式
8. 代价函数的选择
9. 权重初始化的方法
10. 神经元激活函数的种类
11.参加训练模型数据的规模
这十一类超参数。
这些都是可以影响神经网络学习速度和最后分类结果,其中神经网络的学习速度主要根据训练集上代价函数下降的快慢有关,而最后的分类的结果主要跟在验证集上的分类正确率有关。因此可以根据该参数主要影响代价函数还是影响分类正确率进行分类,如图1所示

图1. 十一类超参数的分类情况
因为不同的超参数的类别不同,因此在调整超参数的时候也应该根据对应超参数的类别进行调整。再调整超参数的过程中有根据机理选择超参数的方法,有根据训练集上表现情况选择超参数的方法,也有根据验证集上训练数据选择超参数的方法。他们之间的关系如图2所示。
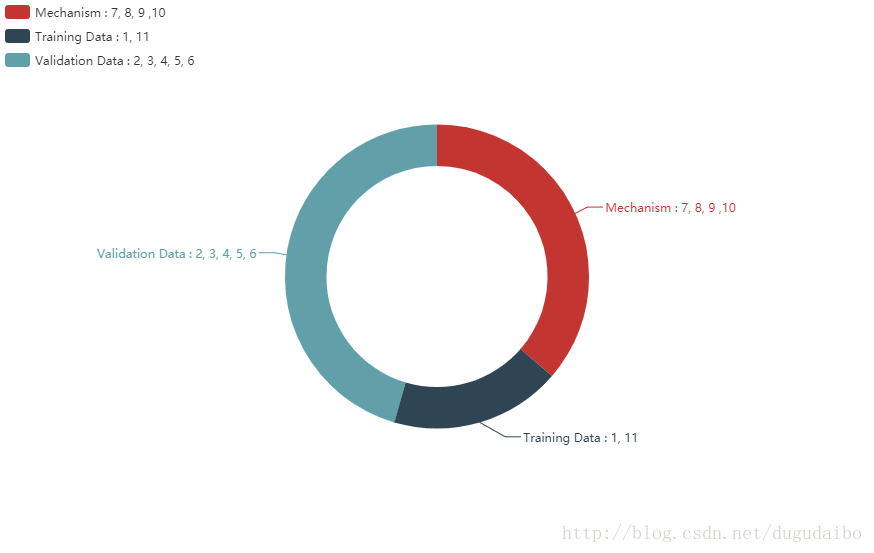
图2. 不同超参数的选择方法不同。
2. 宽泛策略
根据上面的分析我们已经根据机理将神经网络中的神经元的种类、输出层的模式(即是否采用softmax)、代价函数及输出层的编码方式进行了设定。所以在这四个超参数被确定了之后变需要确定其他的超参数了。假设我们是从头开始训练一个神经网络的,我们对于其他参数的取值本身没有任何经验,所以不可能一上来就训练一个很复杂的神经网络,这时就要采用宽泛策略。
宽泛策略的核心在于简化和监控。简化具体体现在,如简化我们的问题,如将一个10分类问题转变为一个2分类问题;简化网络的结构,如从一个仅包含10个神经元你的隐层开始训练,逐渐增加网络的层数和神经元的个数;简化训练用的数据,在简化问题中,我们已经减少了80%的数据量,在这里我们该要精简检验集中数据的数量,因为真正验证的是网络的性能,所以仅用少量的验证集数据也是可以的,如仅采用100个验证集数据。监控具体指的是提高监控的频率,比如说原来是每5000次训练返回一次代价函数或者分类正确率,现在每1000次训练就返回一次。其实可以将“宽泛策略”当作是一种对于网络的简单初始化和一种监控策略,这样可以更加快速地实验其他的超参数,或者甚至接近同步地进行不同参数的组合的评比。
直觉上看,这看起来简化问题和架构仅仅会降低你的效率。实际上,这样能够将进度加快,因为你能够更快地找到传达出有意义的信号的网络。一旦你获得这些信号,你可以尝尝通过微调超参数获得快速的性能提升。
3. 学习率的调整
假设我们运行了三个不同学习速率( η=0.025η=0.025、η=0.25η=0.25、η=2.5η=2.5)的 MNIST 网 络,其他的超参数假设已经设置为进行30回合,minibatch 大小为10,然后 λ=5.0λ=5.0 ,使用50000幅训练图像,训练代价的变化情况如图3
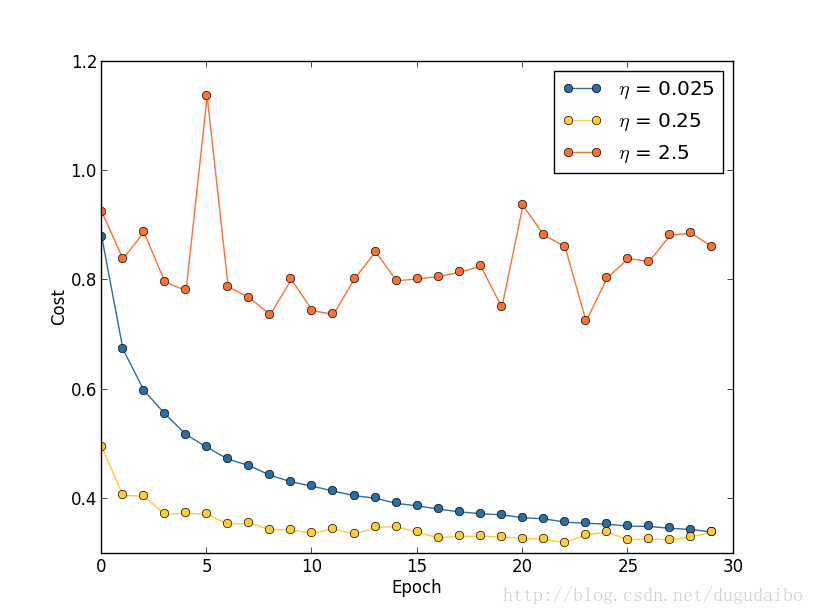
图3. 不同学习率下代价函数曲线的变化情况
因此学习率的调整步骤为:首先,我们选择在训练数据上的代价立即开始下降而非震荡或者增加时的作为 ηη 阈值的估计,不需要太过精确,确定量级即可。如果代价在训练的前面若干回合开始下降,你就可以逐步增加 ηη 的量级,直到你找到一个的值使得在开始若干回合代价就开始震荡或者增加;相反,如果代价函数曲线开始震荡或者增加,那就尝试减小量级直到你找到代价在开始回合就下降的设定,取阈值的一半就确定了学习速率 。在这里使用训练数据的原因是学习速率主要的目的是控制梯度下降的步长,监控训练代价是最好的检测步长过大的方法。
4. 迭代次数
提前停止表示在每个回合的最后,我们都要计算验证集上的分类准确率,当准确率不再提升,就终止它也就确定了迭代次数(或者称回合数)。另外,提前停止也能够帮助我们避免过度拟合。
我们需要再明确一下什么叫做分类准确率不再提升,这样方可实现提前停止。正如我们已经看到的,分类准确率在整体趋势下降的时候仍旧会抖动或者震荡。如果我们在准确度刚开始下降的时候就停止,那么肯定会错过更好的选择。一种不错的解决方案是如果分类准确率在一段时间内不再提升的时候终止。建议在更加深入地理解 网络训练的方式时,仅仅在初始阶段使用 10 回合不提升规则,然后逐步地选择更久的回合,比如 20 回合不提升就终止,30回合不提升就终止,以此类推。
5. 正则化参数
我建议,开始时代价函数不包含正则项,只是先确定 ηη 的值。使用确定出来的 ηη,用验证数据来选择好的 λλ 。尝试从 λ=1λ=1 开始,然后根据验证集上的性能按照因子 10 增加或减少其值。一旦我已经找到一个好的量级,你可以改进 λλ 的值。这里搞定 λλ 后,你就可以返回再重新优化 ηη 。
6. 小批量数据的大小
选择最好的小批量数据大小也是一种折衷。太小了,你不会用上很好的矩阵库的快速计算;太大,你是不能够足够频繁地更新权重的。你所需要的是选择一个折衷的值,可以最大化学习的速度。幸运的是,小批量数据大小的选择其实是相对独立的一个超参数(网络整体架构外的参数),所以你不需要优化那些参数来寻找好的小批量数据大小。因此,可以选择的方式就是使用某些可以接受的值(不需要是最优的)作为其他参数的选择,然后进行不同小批量数据大小的尝试,像上面那样调整 ηη 。画出验证准确率的值随时间(非回合)变化的图,选择哪个得到最快性能的提升的小批量数据大小。得到了小批量数据大小,也就可以对其他的超参数进行优化了。
7. 总体的调参过程
首先应该根据机理确定激活函数的种类,之后确定代价函数种类和权重初始化的方法,以及输出层的编码方式;其次根据“宽泛策略”先大致搭建一个简单的结构,确定神经网络中隐层的数目以及每一个隐层中神经元的个数;然后对于剩下的超参数先随机给一个可能的值,在代价函数中先不考虑正则项的存在,调整学习率得到一个较为合适的学习率的阈值,取阈值的一半作为调整学习率过程中的初始值 ;之后通过实验确定minibatch的大小;之后仔细调整学习率,使用确定出来的 ηη,用验证数据来选择好的 λλ ,搞定 λλ 后,你就可以返回再重新优化 ηη。而学习回合数可以通过上述这些实验进行一个整体的观察再确定。